
Plotlyの散布図(scatter plot)はわかったけど線のプロット(line plot)はどうするのか。今回はpx.lineで折れ線グラフを作成する方法を紹介する。
本記事ではpx(plotly.express)の折れ線グラフの作成方法を紹介するが、go(plotly.graph_objects)での折れ線グラフの作成方法は下記で解説している。
-
-
【Plotlyで折れ線グラフ】go.ScatterでLine Plotを作成する
今回はPlotlyのgo.Scatterを使って折れ線グラフを作成する。px(plotly.express ...
続きを見る
その他にもpx.scatterやgo.Scatterといった散布図グラフの作成方法も解説済み。まずはこの記事から読んでほしい。
本記事ではpx.lineでのグラフの作成方法からプロットのカスタマイズなどを中心に基礎的な内容を解説する。
Python環境は以下。
- Python 3.10.8
- numpy 1.24.0
- plotly 5.11.0
- plotly-orca 3.4.2
参考になるサイト
Plotly公式
その他
本記事のコード全文
下準備のimport
import numpy as np
import pandas as pd
import plotly.graph_objects as go
import plotly.express as px
import plotly.io as pio
まずは下準備としてのimport関連。今回は基本pxを使用するが、一部データ作成や加工をするためにnumpyとpandasを使用する。
また、pxだけでは賄いきれない処理についてはgoを使って実現するのでgoもimport。pioはplotlyでのグラフ保存用のライブラリ。保存の仕方は色々あるがpioその1つだ。
goを使った散布図や折れ線グラフ(go.Scatter)の書き方については以下の記事で詳しく解説している。
-
-
【Plotlyで散布図】go.Scatterのグラフの描き方まとめ
これからPloltyで動くグラフを作りたい、もっとグラフをキ ...
続きを見る
-
-
【Plotlyで折れ線グラフ】go.ScatterでLine Plotを作成する
今回はPlotlyのgo.Scatterを使って折れ線グラフを作成する。px(plotly.express ...
続きを見る
1次元配列をグラフ化
まずは1次元配列からグラフを作成する。px.lineでは引数x, yそれぞれの配列を入れるだけで簡単にグラフを作成可能だ。
import plotly.express as px
import plotly.io as pio
# 1次元配列をグラフ化
fig = px.line(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16])
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_1darray"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
2次元配列をグラフ化
続いては複数データを扱うために2次元配列をグラフ化する。2次元配列はのイメージは以下。
複数のデータを1つの配列に集約させることでデータの管理がしやすい。
y=[[0, 1, 4, 9, 16], [10, 12, 14, 19, 16]]
xを複数指定するとエラー
import plotly.express as px
fig = px.line(
x=[[0, 1, 2, 3, 4], [0, 1, 2, 3, 4]],
y=[[0, 1, 4, 9, 16], [10, 12, 14, 19, 16]],
)
# ValueError: Cannot accept list of column references or list of columns for both `x` and `y`.
px.lineで2次元配列を使う時にxも2次元配列にすると上のようにエラーとなる。
2次元配列を使う時は次に書くように共通のxにしつつ、yだけ2次元配列にする必要がある。
xを共通にするとプロット可能
2次元配列でグラフを作成する際はxを共通にしつつ、yの配列を2次元配列にする。
なので、異なるxのデータを使う場合は1回のpx.lineではグラフ化できず、データを追加する必要がある。これについてはupdate_traceの項目で後述。
import plotly.express as px
import plotly.io as pio
# xを共通にするとプロットが可能
fig = px.line(
x=[0, 1, 2, 3, 4],
y=[[0, 1, 4, 9, 16], [10, 12, 14, 19, 16]],
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_2darray"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
凡例とy軸ラベルを変更する
x軸の配列を共通にすることで2次元配列でもグラフ化できたが、この場合は凡例や縦軸ラベルがわかりづらいものになってしまう。
と言うことで、以下のコードのように凡例タイトルと凡例、y軸タイトルを修正し見やすいグラフにした。
pxは簡単にグラフを作成できる反面、このようなカスタムを施すとなると面倒なのが弱点。修正・編集を楽にしたいならgoを使うのが良い。
import plotly.express as px
import plotly.io as pio
fig = px.line(
x=[0, 1, 2, 3, 4],
y=[[0, 1, 4, 9, 16], [10, 12, 14, 19, 16]],
)
# 各プロットの数だけループさせてnameを変更
for num, _ in enumerate(fig['data']):
fig['data'][num]['name'] = f"y{num}"
# 凡例のタイトルとy軸の軸ラベルを変更
fig.update_layout(legend_title='legend title', yaxis_title='y')
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_2darray_update"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
print(fig)
# Figure({
# 'data': [{'hovertemplate': 'variable=wide_variable_0<br>x=%{x}<br>value=%{y}<extra></extra>',
# 'legendgroup': 'wide_variable_0',
# 'line': {'color': '#636efa', 'dash': 'solid'},
# 'marker': {'symbol': 'circle'},
# 'mode': 'lines',
# 'name': 'wide_variable_0',
# 'orientation': 'v',
# 'showlegend': True,
# 'type': 'scatter',
# 'x': array([0, 1, 2, 3, 4]),
# 'xaxis': 'x',
# 'y': array([ 0, 1, 4, 9, 16]),
# 'yaxis': 'y'},
# {'hovertemplate': 'variable=wide_variable_1<br>x=%{x}<br>value=%{y}<extra></extra>',
# 'legendgroup': 'wide_variable_1',
# 'line': {'color': '#EF553B', 'dash': 'solid'},
# 'marker': {'symbol': 'circle'},
# 'mode': 'lines',
# 'name': 'wide_variable_1',
# 'orientation': 'v',
# 'showlegend': True,
# 'type': 'scatter',
# 'x': array([0, 1, 2, 3, 4]),
# 'xaxis': 'x',
# 'y': array([10, 12, 14, 19, 16]),
# 'yaxis': 'y'}],
# 'layout': {'legend': {'title': {'text': 'variable'}, 'tracegroupgap': 0},
# 'margin': {'t': 60},
# 'template': '...',
# 'xaxis': {'anchor': 'y', 'domain': [0.0, 1.0], 'title': {'text': 'x'}},
# 'yaxis': {'anchor': 'x', 'domain': [0.0, 1.0], 'title': {'text': 'value'}}}
# })
print(fig)
# Figure({
# 'data': [{'hovertemplate': 'variable=wide_variable_0<br>x=%{x}<br>value=%{y}<extra></extra>',
# 'legendgroup': 'wide_variable_0',
# 'line': {'color': '#636efa', 'dash': 'solid'},
# 'marker': {'symbol': 'circle'},
# 'mode': 'lines',
# 'name': 'y0',
# 'orientation': 'v',
# 'showlegend': True,
# 'type': 'scatter',
# 'x': array([0, 1, 2, 3, 4]),
# 'xaxis': 'x',
# 'y': array([ 0, 1, 4, 9, 16]),
# 'yaxis': 'y'},
# {'hovertemplate': 'variable=wide_variable_1<br>x=%{x}<br>value=%{y}<extra></extra>',
# 'legendgroup': 'wide_variable_1',
# 'line': {'color': '#EF553B', 'dash': 'solid'},
# 'marker': {'symbol': 'circle'},
# 'mode': 'lines',
# 'name': 'y1',
# 'orientation': 'v',
# 'showlegend': True,
# 'type': 'scatter',
# 'x': array([0, 1, 2, 3, 4]),
# 'xaxis': 'x',
# 'y': array([10, 12, 14, 19, 16]),
# 'yaxis': 'y'}],
# 'layout': {'legend': {'title': {'text': 'legend title'}, 'tracegroupgap': 0},
# 'margin': {'t': 60},
# 'template': '...',
# 'xaxis': {'anchor': 'y', 'domain': [0.0, 1.0], 'title': {'text': 'x'}},
# 'yaxis': {'anchor': 'x', 'domain': [0.0, 1.0], 'title': {'text': 'y'}}}
# })
pandasデータフレームをグラフ化
ここまで配列からグラフを作成したが、実はpxはpandasのデータフレームからグラフを作るのが定番であり、データフレームを使う方が汎用性が高い。
ここからはpandasのデータフレームでグラフを作成する方法を解説する。ただし、使用するデータフレームは以下の形式であることが前提だ。
# data x y ...
# 12 data_1 x0 y1_0 ...
# 13 data_1 x1 y1_1 ...
# 14 data_1 x2 y1_2 ...
# 15 data_1 x3 y1_3 ...
# 16 data_1 x4 y1_4 ...
# ... ... ... ... ...
# 1603 data_n x0 yn_0 ...
# 1604 data_n x1 yn_1 ...
# 1605 data_n x2 yn_2 ...
# 1606 data_n x3 yn_3 ...
# 1607 data_n x4 yn_4 ...
要するに、1つのカラムに全てのデータが入っているということ。例えばdataカラムにはそれぞれのデータの名称が記載され、それぞれのx, yがその横に羅列されている。
イメージしづらい人は一度、以下で使用するデータフレームを自分で確認してほしい。
pandasではカラム名を指定するだけ
pandasのデータフレームを使ってpxのグラフを作成するには引数にデータフレームと使用するx, yのカラム名を指定する。
ここではカナダだけのデータフレームを使用し、xには年(year)、yには平均寿命(lifeExp)を指定した。
配列を使用した時のように、データ自体を引数に入れないので注意。
import plotly.express as px
import plotly.io as pio
# pandasのデータフレームではカラム名を指定すればプロット可能
# カナダのデータだけ抽出
df = px.data.gapminder().query("country=='Canada'")
# print(df)
# # country continent year lifeExp pop gdpPercap iso_alpha iso_num
# # 240 Canada Americas 1952 68.750 14785584 11367.16112 CAN 124
# # 241 Canada Americas 1957 69.960 17010154 12489.95006 CAN 124
# # 242 Canada Americas 1962 71.300 18985849 13462.48555 CAN 124
# # 243 Canada Americas 1967 72.130 20819767 16076.58803 CAN 124
# # 244 Canada Americas 1972 72.880 22284500 18970.57086 CAN 124
# # 245 Canada Americas 1977 74.210 23796400 22090.88306 CAN 124
# # 246 Canada Americas 1982 75.760 25201900 22898.79214 CAN 124
# # 247 Canada Americas 1987 76.860 26549700 26626.51503 CAN 124
# # 248 Canada Americas 1992 77.950 28523502 26342.88426 CAN 124
# # 249 Canada Americas 1997 78.610 30305843 28954.92589 CAN 124
# # 250 Canada Americas 2002 79.770 31902268 33328.96507 CAN 124
# # 251 Canada Americas 2007 80.653 33390141 36319.23501 CAN 124
fig = px.line(df, x="year", y="lifeExp", title='Life expectancy in Canada')
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_1column"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
全カラムをグラフ化
カラム名を指定するので、そのカラムに複数のデータが入っていれば自動で区別してグラフ化することも可能。ここではヨーロッパのデータにのみ絞ってグラフ化した。
ただし、px.lineの引数でどのカラムでデータを区切るか指定する必要がある。ここでは引数colorを指定したが、後で詳しく解説する。
import plotly.express as px
import plotly.io as pio
# colorでデータ分けする
# ヨーロッパのデータだけ抽出
df = px.data.gapminder().query("continent=='Europe'")
# print(df)
# # country continent year ... gdpPercap iso_alpha iso_num
# # 12 Albania Europe 1952 ... 1601.056136 ALB 8
# # 13 Albania Europe 1957 ... 1942.284244 ALB 8
# # 14 Albania Europe 1962 ... 2312.888958 ALB 8
# # 15 Albania Europe 1967 ... 2760.196931 ALB 8
# # 16 Albania Europe 1972 ... 3313.422188 ALB 8
# # ... ... ... ... ... ... ... ...
# # 1603 United Kingdom Europe 1987 ... 21664.787670 GBR 826
# # 1604 United Kingdom Europe 1992 ... 22705.092540 GBR 826
# # 1605 United Kingdom Europe 1997 ... 26074.531360 GBR 826
# # 1606 United Kingdom Europe 2002 ... 29478.999190 GBR 826
# # 1607 United Kingdom Europe 2007 ... 33203.261280 GBR 826
# # [360 rows x 8 columns]
fig = px.line(df, x="year", y="lifeExp", color='country')
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_some_data"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
複数カラムをカラム名で指定してグラフ化
ただ、使用するデータフレームの全てのカラムをグラフ化したくはない時もあるだろう。その時はデータを指定することが可能。
ここでは元々のデータフレームのカラムを国別に変換し、国単位でカラムを指定してグラフ化した。
もちろん他の方法もあるので、ぜひ色々と探してほしい。
import plotly.express as px
import plotly.io as pio
# 複数カラム名を配列で指定し複数プロット
# ヨーロッパのデータだけ抽出
df = px.data.gapminder().query("continent=='Europe'")
print(df['country'].unique())
# ['Albania' 'Austria' 'Belgium' 'Bosnia and Herzegovina' 'Bulgaria'
# 'Croatia' 'Czech Republic' 'Denmark' 'Finland' 'France' 'Germany'
# 'Greece' 'Hungary' 'Iceland' 'Ireland' 'Italy' 'Montenegro' 'Netherlands'
# 'Norway' 'Poland' 'Portugal' 'Romania' 'Serbia' 'Slovak Republic'
# 'Slovenia' 'Spain' 'Sweden' 'Switzerland' 'Turkey' 'United Kingdom']
# 国ごとの平均寿命を年ごとに集計
df_wide = df.pivot(index='year', columns='country', values='lifeExp').reset_index()
print(df_wide)
# country year Albania Austria ... Switzerland Turkey United Kingdom
# 0 1952 55.230 66.800 ... 69.620 43.585 69.180
# 1 1957 59.280 67.480 ... 70.560 48.079 70.420
# 2 1962 64.820 69.540 ... 71.320 52.098 70.760
# 3 1967 66.220 70.140 ... 72.770 54.336 71.360
# 4 1972 67.690 70.630 ... 73.780 57.005 72.010
# 5 1977 68.930 72.170 ... 75.390 59.507 72.760
# 6 1982 70.420 73.180 ... 76.210 61.036 74.040
# 7 1987 72.000 74.940 ... 77.410 63.108 75.007
# 8 1992 71.581 76.040 ... 78.030 66.146 76.420
# 9 1997 72.950 77.510 ... 79.370 68.835 77.218
# 10 2002 75.651 78.980 ... 80.620 70.845 78.471
# 11 2007 76.423 79.829 ... 81.701 71.777 79.425
print(df_wide.columns.values)
# ['year' 'Albania' 'Austria' 'Belgium' 'Bosnia and Herzegovina' 'Bulgaria'
# 'Croatia' 'Czech Republic' 'Denmark' 'Finland' 'France' 'Germany'
# 'Greece' 'Hungary' 'Iceland' 'Ireland' 'Italy' 'Montenegro' 'Netherlands'
# 'Norway' 'Poland' 'Portugal' 'Romania' 'Serbia' 'Slovak Republic'
# 'Slovenia' 'Spain' 'Sweden' 'Switzerland' 'Turkey' 'United Kingdom']
fig = px.line(df_wide, x="year", y=['France', 'Germany', 'Spain'])
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_some_columns"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
複数カラムをインデックスで指定してグラフ化
使用するカラムはカラム名でなくインデックスで指定することも可能。フランス、ドイツ、スペインのカラムのインデックスはそれぞれ10, 11, 26だったのでこれらを指定した。
import plotly.express as px
import plotly.io as pio
# 複数カラムのグラフ化はインデックス指定でモ可能
df = px.data.gapminder().query("continent=='Europe'")
df_wide = df.pivot(index='year', columns='country', values='lifeExp').reset_index()
# グラフ化したいカラムをインデックスで指定
fig = px.line(df_wide, x="year", y=df_wide.columns[[10, 11, 26]])
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_some_columns_index"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
プロットのカスタマイズ
ここまでで配列やpandasのデータフレームを使用してpx.lineのグラフを作成したが、以下では作成したプロットの色などをカスタマイズする方法を解説する。
colorでプロットに色をつける
px.lineでプロットする際、データを区別するカラム名を引数colorで指定すると、プロット同士を色分けしてくれる。ここではオセアニアの国を色分けした。
import plotly.express as px
import plotly.io as pio
# colorでプロットに色をつける
df = px.data.gapminder().query("continent=='Oceania'")
print(df)
# country continent year ... gdpPercap iso_alpha iso_num
# 60 Australia Oceania 1952 ... 10039.59564 AUS 36
# 61 Australia Oceania 1957 ... 10949.64959 AUS 36
# 62 Australia Oceania 1962 ... 12217.22686 AUS 36
# 63 Australia Oceania 1967 ... 14526.12465 AUS 36
# 64 Australia Oceania 1972 ... 16788.62948 AUS 36
# 65 Australia Oceania 1977 ... 18334.19751 AUS 36
# 66 Australia Oceania 1982 ... 19477.00928 AUS 36
# 67 Australia Oceania 1987 ... 21888.88903 AUS 36
# 68 Australia Oceania 1992 ... 23424.76683 AUS 36
# 69 Australia Oceania 1997 ... 26997.93657 AUS 36
# 70 Australia Oceania 2002 ... 30687.75473 AUS 36
# 71 Australia Oceania 2007 ... 34435.36744 AUS 36
# 1092 New Zealand Oceania 1952 ... 10556.57566 NZL 554
# 1093 New Zealand Oceania 1957 ... 12247.39532 NZL 554
# 1094 New Zealand Oceania 1962 ... 13175.67800 NZL 554
# 1095 New Zealand Oceania 1967 ... 14463.91893 NZL 554
# 1096 New Zealand Oceania 1972 ... 16046.03728 NZL 554
# 1097 New Zealand Oceania 1977 ... 16233.71770 NZL 554
# 1098 New Zealand Oceania 1982 ... 17632.41040 NZL 554
# 1099 New Zealand Oceania 1987 ... 19007.19129 NZL 554
# 1100 New Zealand Oceania 1992 ... 18363.32494 NZL 554
# 1101 New Zealand Oceania 1997 ... 21050.41377 NZL 554
# 1102 New Zealand Oceania 2002 ... 23189.80135 NZL 554
# 1103 New Zealand Oceania 2007 ... 25185.00911 NZL 554
# [24 rows x 8 columns]
# colorで色分けしたいカラム名を指定
fig = px.line(df, x="year", y="lifeExp", color='country')
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_color"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
colorを指定しないと1つのグラフになる
一方で引数colorを指定しない場合、どのカラムでデータを区別したらいいのか判別できない。なので1つのデータとして認識されグラフ化される。
上のグラフでは左端と右端で折り返されているのがわかる。
import plotly.express as px
import plotly.io as pio
# カラム指定時に色分けを指定しないと1つのグラフになる
df = px.data.gapminder().query("continent=='Oceania'")
fig = px.line(df, x="year", y="lifeExp")
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_color_drop"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
markersでプロットのマーカーをつける
引数markers=Trueにすることでプロットにマーカー(シンボル)を追加することが可能だ。
デフォルトでは線のみなので、横軸のデータの位置を明確にしたいときは使用するとわかりやすい。
import plotly.express as px
import plotly.io as pio
# markersでマーカーをつける
df = px.data.gapminder().query("continent=='Oceania'")
fig = px.line(df, x="year", y="lifeExp", color='country', markers=True)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_markers"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
symbolでマーカーの形状を指定
引数symbolを使用することでデータをマーカーで区別することが可能。ただし、colorを指定しないと各データが同じ色で表現されるので注意。
あくまでもcolorを指定しつつ、その補助としてsymbolを指定する方がグラフとして見やすい。
import plotly.express as px
import plotly.io as pio
# symbolでマーカーの形状でデータを分ける
df = px.data.gapminder().query("continent=='Oceania'")
fig = px.line(df, x="year", y="lifeExp", symbol='country')
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_symbol"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
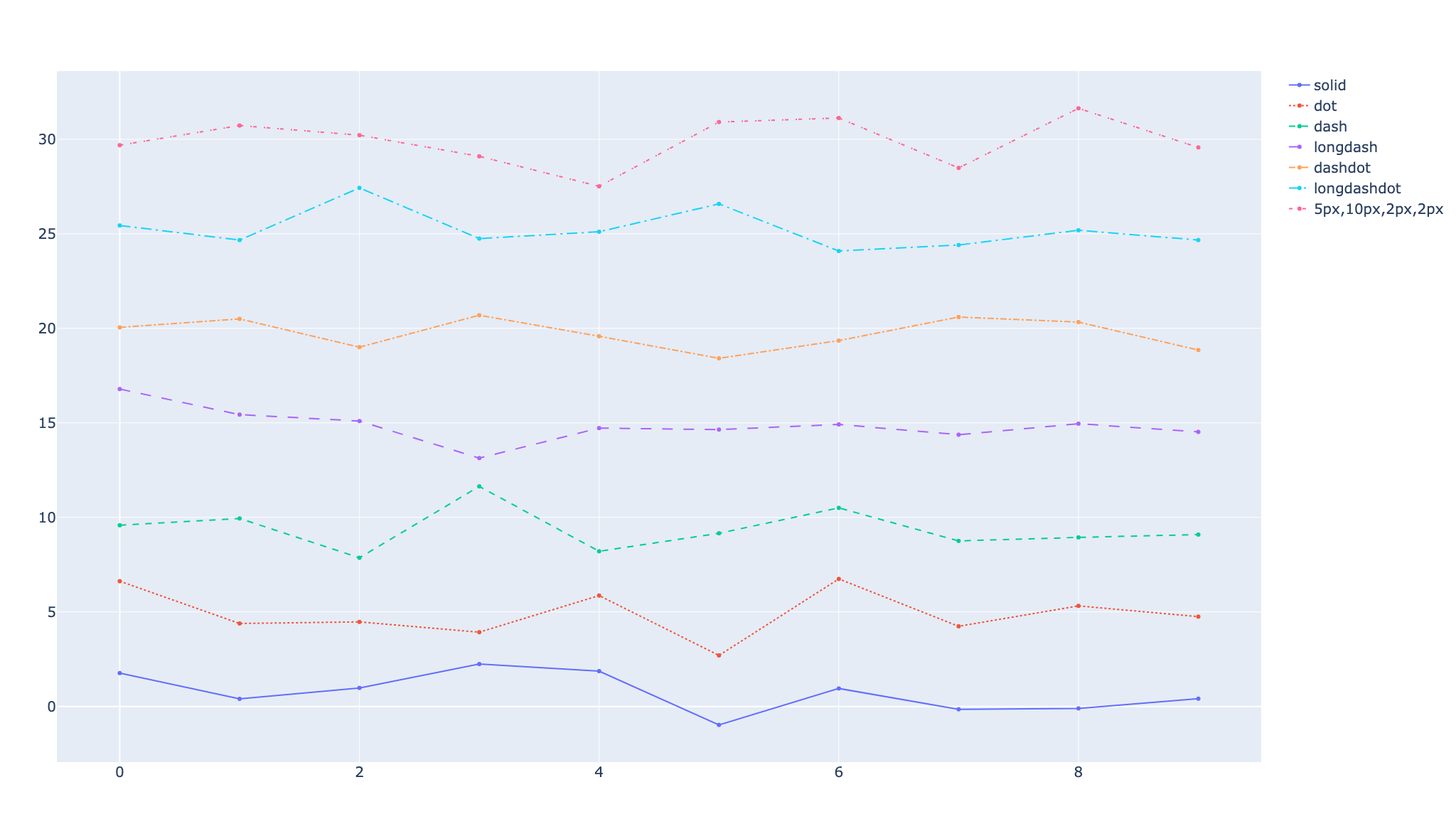
line_dashでプロット線の種類を変える
また、引数line_dashを指定することで線の種類でもデータを分けることが可能だ。この時もcolorを指定しないと上のグラフのように同じ色で表示されるので注意。
import plotly.express as px
import plotly.io as pio
# line_dashdで線の形状でデータを分ける
df = px.data.gapminder().query("continent=='Oceania'")
fig = px.line(df, x="year", y="lifeExp", line_dash='country')
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_line_dash"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
map系の引数で色やマーカーを指定
px.lineで引数color, symbol, line_dashを指定することで自動でデータ分けしてくれるが、どれも自動で色やシンボルの形状、線の種類がつく。
これらを自分で指定するにはmapと名のついた引数を使用する。それぞれの引数でデータごとに設定することで自由にデータの区別をつけられる。
import plotly.express as px
import plotly.io as pio
# map系の引数で色やマーカーを指定
df = px.data.gapminder().query("continent=='Oceania'")
fig = px.line(
df, x="year", y="lifeExp",
color='country', symbol='country', line_dash='country',
color_discrete_map={'Australia': '#E4002B', 'New Zealand': '#012169'},
symbol_map={'Australia': 'square', 'New Zealand': 'x'},
line_dash_map={'Australia': 'dot', 'New Zealand': 'dashdot'}
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_map"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
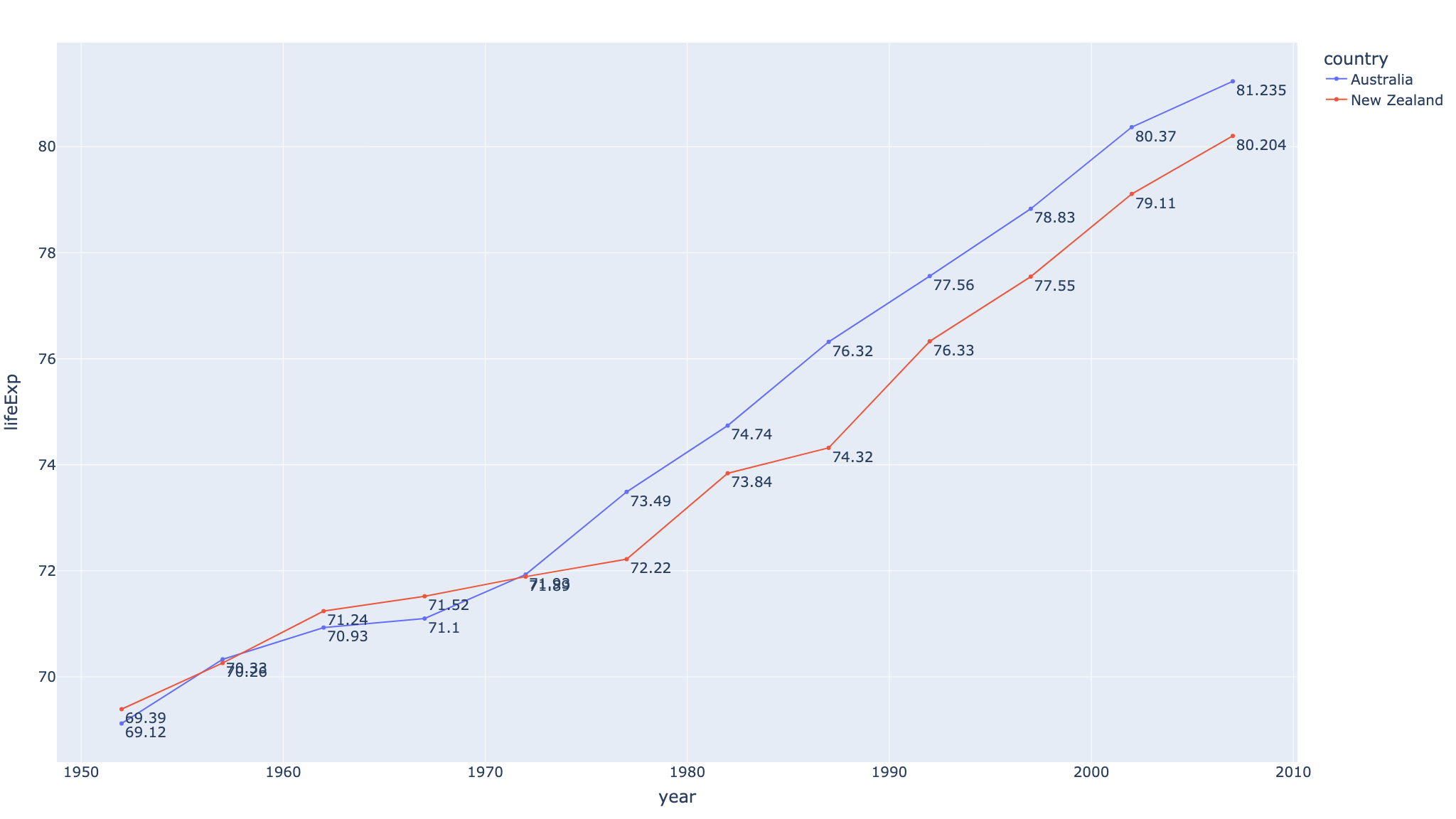
textでプロットに文字を追加
引数textでグラフ化したデータ点にテキストを追加することが可能だ。引数textもこれまでと同様カラム名を指定することで自動でテキストを追加してくれる。
ただ、デフォルトではプロット点の中央にテキストを配置してしまい見づらい。ということで上のグラフではプロット点の右下にテキストが来るように修正した。
import plotly.express as px
import plotly.io as pio
# textでプロットに文字を追加
df = px.data.gapminder().query("continent=='Oceania'")
# textに追加したい文字のカラムを指定
fig = px.line(df, x="year", y="lifeExp", color='country', text='lifeExp')
# デフォルトはテキストがプロットの中心に来るので下に移動
fig.update_traces(textposition="bottom right")
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_text"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
fig.add_traceでプロットの追加や色の変更
pxではpandasのデータフレームをグラフ化することが多い。しかし、データフレームとは別に配列のデータを追加してグラフ化したい時がある。
ここではデータフレームをpx.lineでグラフ化したfigに、fig.add_traceを使って配列データを追加する方法を紹介する。
なお、pandasのデータフレームのデータを追加したい場合は、pandas同士の結合をすればいいのでここでは割愛する。
goを使ってプロットを追加
fig.add_traceデータを追加する方法の王道はgoを使うことだ。goのプロットは複雑になりがちだが、その分、自由度高くプロットすることが可能。
ここでは横軸xは元々のデータフレームの値を使用し、yはxの配列の個数だけ乱数を作成した。
この乱数をgoの散布図go.Scatterで使用し、グラフ形状をmode=’line’で折れ線形式にすることでpx.lineと似たグラフを作成可能。
goでの折れ線グラフの作成方法は以下の記事で解説している。
-
-
【Plotlyで折れ線グラフ】go.ScatterでLine Plotを作成する
今回はPlotlyのgo.Scatterを使って折れ線グラフを作成する。px(plotly.express ...
続きを見る
なお、px.lineで作成したグラフに近づけるために引数hovertemplateを追加したが、これはマウスオーバー時のホバー内容のテンプレート。
ホバー機能を使用しない場合は不要だ。
import numpy as np
import plotly.graph_objects as go
import plotly.express as px
import plotly.io as pio
# fig.add_traceとgoでプロットの追加
df = px.data.gapminder().query("continent=='Oceania'")
fig = px.line(df, x="year", y="lifeExp", color='country')
# dfの各国のデータの数だけ架空のデータを作成
x = fig['data'][0]['x']
# yの値は乱数で作成
np.random.seed(0)
y = np.random.randint(65, 90, len(x))
print(x)
# [1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 2002 2007]
print(y)
# [77 80 86 65 68 68 72 74 84 86 83 69]
# マウスオーバー時のホバー内容
hover = 'country=fictitious<br>year=%{x}<br>lifeExp=%{y}<extra></extra>'
fig.add_trace(
go.Scatter(x=x, y=y, name='fictitious', mode='lines', hovertemplate=hover)
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_add_trace_go"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
figを使ってプロットを追加
一方でgoを使用せずpxだけで完結させる方法でもプロットの追加は可能。ただし、この場合はfigのdata部分を編集しないとpx.lineのグラフに近づけられないので注意。
figのデータ部分はfig[’data’]で取得可能、今回は1データだけなので初めの0番目だけ使用している。
import numpy as np
import plotly.express as px
import plotly.io as pio
# fig.add_traceとfigでプロットの追加
df = px.data.gapminder().query("continent=='Oceania'")
fig = px.line(df, x="year", y="lifeExp", color='country')
# dfの各国のデータの数だけ架空のデータを作成
x = fig['data'][0]['x']
# yの値は乱数で作成
np.random.seed(0)
y = np.random.randint(65, 90, len(x))
hover = 'country=fictitious<br>year=%{x}<br>lifeExp=%{y}<extra></extra>'
print(go.Scatter(x=x, y=y, name='fictitious', mode='lines', hovertemplate=hover))
# Scatter({
# 'hovertemplate': 'country=fictitious<br>year=%{x}<br>lifeExp=%{y}<extra></extra>',
# 'mode': 'lines',
# 'name': 'fictitious',
# 'x': array([1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, 1997, 2002, 2007]),
# 'y': array([77, 80, 86, 65, 68, 68, 72, 74, 84, 86, 83, 69])
# })
# マウスオーバー時のホバー内容
hover = 'country=fictitious<br>year=%{x}<br>lifeExp=%{y}<extra></extra>'
# figを作成し、データ部分を編集
add_fig = px.line(x=x, y=y)
add_fig['data'][0]['name'] = 'fictitious' # プロット名
add_fig['data'][0]['line_color'] = 'green' # プロットの色
add_fig['data'][0]['showlegend'] = True # 凡例を表示
add_fig['data'][0]['hovertemplate'] = hover # ホバーの中身
print(add_fig['data'][0])
# Scatter({
# 'hovertemplate': 'country=fictitious<br>year=%{x}<br>lifeExp=%{y}<extra></extra>',
# 'legendgroup': '',
# 'line': {'color': 'green', 'dash': 'solid'},
# 'marker': {'symbol': 'circle'},
# 'mode': 'lines',
# 'name': 'fictitious',
# 'orientation': 'v',
# 'showlegend': True,
# 'x': array([1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, 1997, 2002, 2007]),
# 'xaxis': 'x',
# 'y': array([77, 80, 86, 65, 68, 68, 72, 74, 84, 86, 83, 69]),
# 'yaxis': 'y'
# })
fig.add_trace(add_fig['data'][0])
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_add_trace_fig"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
横軸が日付のグラフで範囲指定
pandasのデータフレームでは横軸が日付のデータを扱うことも多い。ここでは横軸が日付のグラフの範囲指定や日付間隔を変更する方法を解説する。
range_xで期間指定
横軸の範囲を指定するにはrange_xを使用する。今回使用するデータフレームは横軸のyearが文字列の年なので、range_xもそのまま文字列で指定可能。
もちろん一度datetimeに変換してから、datetimeでrange_xの期間指定してもいい。
import plotly.express as px
import plotly.io as pio
# range_xで横軸の範囲を指定
df = px.data.gapminder().query("continent=='Oceania'")
print(df['year'].unique())
# [1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 2002 2007]
# range_xで横軸の表示範囲を指定
fig = px.line(df, x="year", y="lifeExp", color='country', range_x=['1972', '2002'])
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_range_x"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
range_xではそのまま以降の指定ができない
#片方だけ範囲指定はできない
fig = px.line(df, x="year", y="lifeExp", color='country', range_x=['1972',])
# The 'range' property is an info array that may be specified as:
# * a list or tuple of 2 elements where:
# (0) The 'range[0]' property accepts values of any type
# (1) The 'range[1]' property accepts values of any type
range_xは期間を指定する引数なので「以降」といった片方だけ指定することはできない。
しかし、以下のように元々のデータフレームの期間の最大値を使用することで、実質「以降」のグラフを作成することが可能だ。
ただし、range_xの指定の片方を文字列、片方をdatetimeのように異なる文字列にすると範囲が適用されないので注意。ここではどちらも文字列に統一した。
import pandas as pd
import plotly.express as px
import plotly.io as pio
# range_xで横軸の範囲を以降の形式で指定
df = px.data.gapminder().query("continent=='Oceania'")
df['year'] = pd.to_datetime(df['year'], format='%Y')
# データフレームの横軸の最大値を使用
latest_date = (pd.to_datetime(df['year'].unique())).max()
fig = px.line(
df, x="year", y="lifeExp", color='country',
# range_xで
range_x=['1972', latest_date.strftime('%Y')]
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_range_x_from"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
dtickで日付間隔を変える
レイアウトのx軸でdtickを指定するとグラフの横軸の表示間隔を変更することが可能だ。ただし、dtickを使用するには横軸をdatetime形式にする必要があるので注意。
間隔は「月」単位なので、3ヶ月単位にするならM3、4年単位にするなら12 × 4でM48にする。ここでは10年単位のM120とした。
import pandas as pd
import plotly.express as px
import plotly.io as pio
# dtickで日付の間隔を変更
df = px.data.gapminder().query("continent=='Oceania'")
# dtickを使うにはdatetime形式にする必要がある
df['year'] = pd.to_datetime(df['year'], format='%Y')
# print(df['year'])
# # 60 1952-01-01
# # 61 1957-01-01
# # 62 1962-01-01
# # 63 1967-01-01
# # 64 1972-01-01
# # 65 1977-01-01
# # 66 1982-01-01
# # 67 1987-01-01
# # 68 1992-01-01
# # 69 1997-01-01
# # 70 2002-01-01
# # 71 2007-01-01
# # 1092 1952-01-01
# # 1093 1957-01-01
# # 1094 1962-01-01
# # 1095 1967-01-01
# # 1096 1972-01-01
# # 1097 1977-01-01
# # 1098 1982-01-01
# # 1099 1987-01-01
# # 1100 1992-01-01
# # 1101 1997-01-01
# # 1102 2002-01-01
# # 1103 2007-01-01
# # Name: year, dtype: datetime64[ns]
fig = px.line(df, x="year", y="lifeExp", color='country')
# dtickは月単位で指定。M120は10年単位
fig.update_xaxes(dtick=f"M{12 * 10}")
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_dtick"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
連結散布図を作成
連結散布図とは散布図の一種で、プロット点を時系列でつないだグラフのことだ。連結散布図を使うことで2つの基準でデータの関連の時間的な動きを確認することできる。
難しそうに感じるかもしれないが、ただ単にプロット点に時系列データ(年や日付など)を追加しただけだ。
上のグラフでは横軸をlifeExp(平均寿命)、縦軸をgdpPercap(1人当たりGDP)とし、引数textに時系列のyearを指定した。
import plotly.express as px
import plotly.io as pio
# 連結散布図を作成
df = px.data.gapminder().query("country in ['Canada', 'Botswana']")
# 横軸と縦軸を数値にしてtextを時間にする
fig = px.line(df, x="lifeExp", y="gdpPercap", color="country", text="year")
fig.update_traces(textposition="bottom right")
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-line' # 保存ファイル名の接頭辞
save_name = f"{prefix}_connected_scatterplots"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
簡単に折れ線グラフを作成する
今回はpx.lineを使用しpxで折れ線グラフを作成する方法を解説した。pxはpandasのデータフレームを使うことで簡単にある程度のグラフを作成できる。
その分カスタム性には乏しいが、標準的なクオリティのグラフを作成したい人におすすめなので、ぜひ使いこなしてほしい。
Plotlyのグラフ化や考え方を学びつつ折れ線グラフを作成するにはgoがおすすめ。以下の記事では折れ線グラフを
-
-
【Plotlyで折れ線グラフ】go.ScatterでLine Plotを作成する
今回はPlotlyのgo.Scatterを使って折れ線グラフを作成する。px(plotly.express ...
続きを見る
以下の記事では散布図を作成する方法を解説している。
-
-
【Plotlyで散布図】px.scatterのグラフの描き方まとめ
これからPloltyで動くグラフを作りたい、もっとグラフをキ ...
続きを見る
また、Plotlyではグラフにボタンを追加しプロットの表示を切り替えることも可能だ。
以下の記事で解説しているので、より自由度の高いグラフを作成したい人は併せて読んでほしい。
-
-
【Plotly&ボタン】updatemenusとbuttonsでボタン機能を追加
Plotlyはプロットしたデータを動かすことができるのが大き ...
続きを見る
-
-
【Plotly&ボタン】updatemenusのargs2で2回目のボタン押下機能を追加
今回はPlotlyのボタン機能に2回目のボタン押下の処理を追加& ...
続きを見る