今回は2022年末にOpenAIがリリースし公開5日程度でユーザー数が100万人を達成した話題のAI(人工知能)モデルのChatGPTをPythonで動かす方法を紹介する。
もちろん公式サイトで普通に動作させるのも1つの手であり、一般人はこの方法しか知らない。ただ、Pythonを使うことでプログラムで動かすことが可能だ。応用すれば自サービスにも使えそうだ。
本記事ではChatGPTのAPI Keyとライブラリopenaiのopenai.Completion.createを使用する。
Python環境は以下。
- Python 3.9.6
参考になるサイト
ChatGPT公式
OpenAI公式
Qiita
本記事のコード全文
下準備のimport
import openai
本記事では主にOpenAIのライブラリopenaiを使用する。ChatGPTをPythonで実行する方法は多々あるが、安定的に使用できるのがこのopanaiだ。
openaiをインストールしていない人はまずは下記コマンドよりopenaiをインストールしてほしい。
pip install openai
API Keyを取得
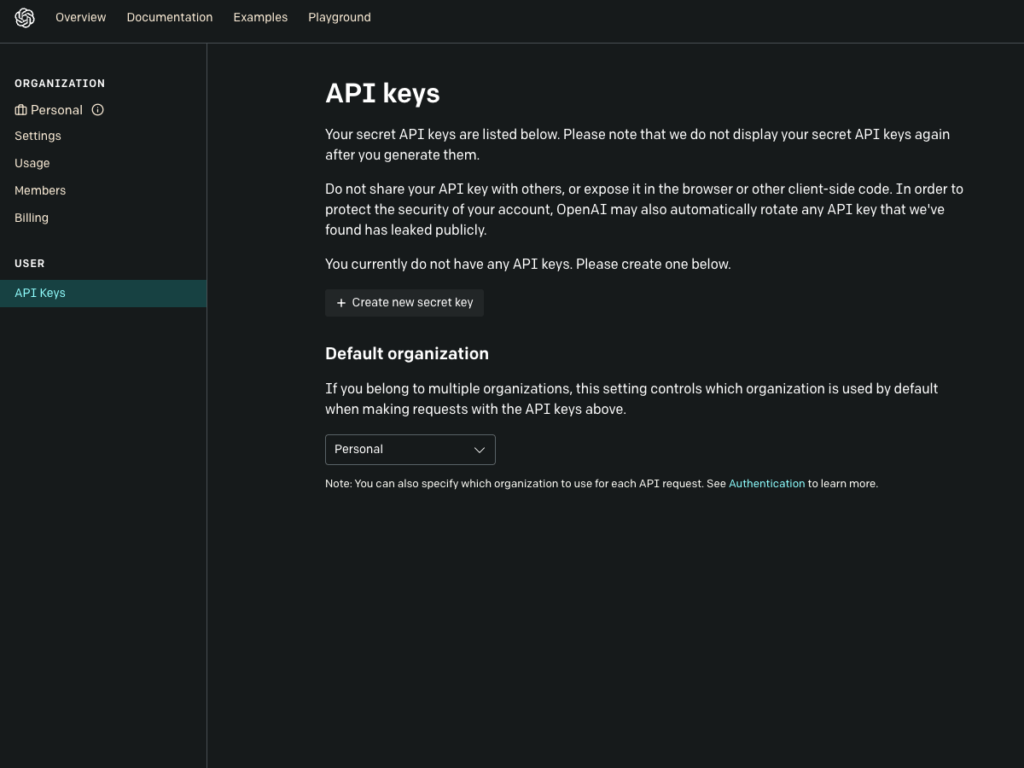
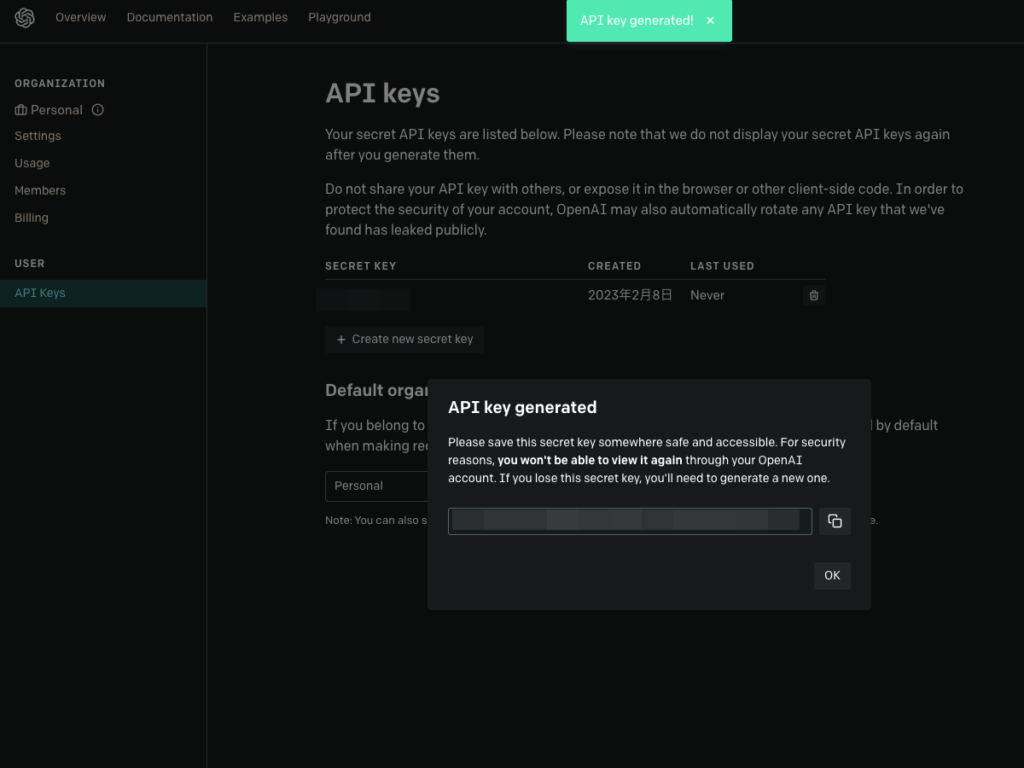
OpenAIの下記のAPI Key取得のページにアクセスし、「Create new secret key」からAPI Keyを取得可能。
この時、注意文にも書いてあるように、生成したAPI Keyは再度表示されることはない。この後も使用するので必ず控えておこう。
なお、API Keyを忘れてしまったら再度発行することになるので注意。
Please note that we do not display your secret API keys again after you generate them.
API Keyを取得できたらほぼ終了。あとはスクリプトを書いて実行するのみ。
openai.Completion.createで試してみる
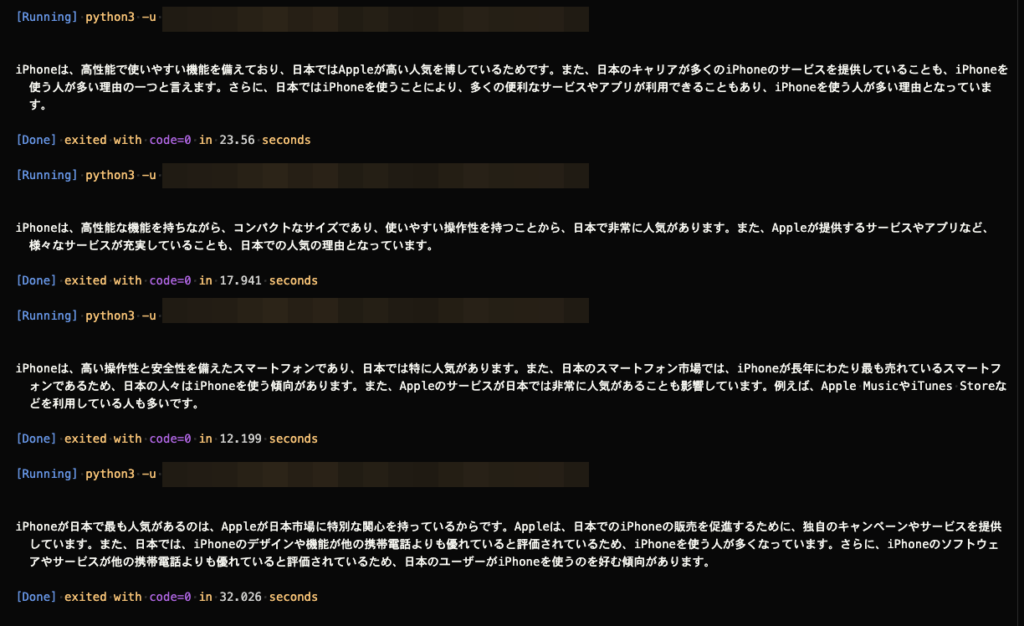
ここでは取得したAPI Keyをopenai.Completion.createで使ってスクリプトを書き実行してみた。出力された結果が上の回答、問いは以下。日本人が気になるiPhoneの疑問。
日本にiPhoneを使う人が多いのはなぜ?
もちろんこれは推論なので毎回同じ答えが返ってくるわけではない。大体の内容が同じでもニュアンスが異なっていたり内容が細かくなっていたりする。
また、ChatGPTは1つの問いで完結せず、続けて問い続けると前の問いを踏まえて回答してくれる。なので質問を追うごとに内容が細かくなるだろう。
import openai
# API Keyの設定
openai.api_key = "(ここにAPI Key)"
# モデルの指定
model_engine = "text-davinci-003"
# 指示内容
prompt = "日本にiPhoneを使う人が多いのはなぜ?"
# 推論の実行
completion = openai.Completion.create(
model=model_engine,
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
temperature=0.5,
)
# 結果
response = completion.choices[0].text
print(response)
スクリプトも書いてくれる
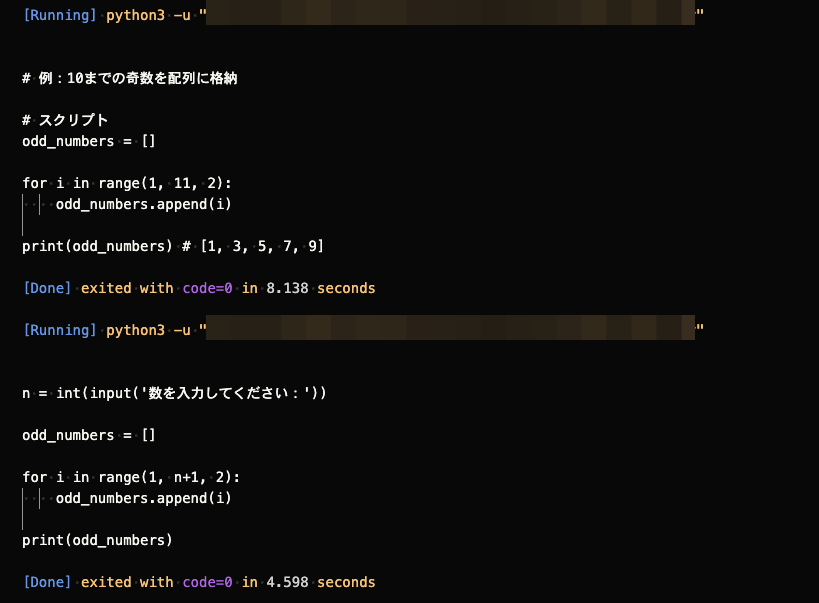
文章ペースの回答はもちろんのこと、上の画像のようにスクリプトを記述することも可能だ。問いは以下。初心者だと悩みがちなもの。
pythonで任意の数までの奇数を配列に格納するスクリプトを書いてください。
何度か聞くとそれぞれで異なる回答をもらえるので、複数の方法を知りたい人は参考にしてほしい。
import openai
#スクリプトも書いてくれる
# API Keyの設定
openai.api_key = "(ここにAPI Key)"
# モデルの指定
model_engine = "text-davinci-003"
# 指示内容
prompt = "pythonで任意の数までの奇数を配列に格納するスクリプトを書いてください。"
# 推論の実行
completion = openai.Completion.create(
model=model_engine,
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
temperature=0.5,
)
# 結果
response = completion.choices[0].text
print(response)
openai.Completion.createの各変数を見る
openai.Completion.createを使うことでChatGPTを使うことができたが、各変数の意味を知っておかないと何をしているかがさっぱりわからない。なので以下にて簡単に解説しておく。
model: APIで使用できるモデル- 引数
engineもあるが非推奨
- 引数
prompt: 指示内容max_tokens: 出力内容の最大単語数- モデルによって異なる
n: 生成する結果数stop: トークンの生成を停止する文章・文字temperature: 0(ランダム)から2(確定的)な答えを生成
これらの他にも多数の引数があるが、詳しくは公式ドキュメントを参照いただきたい。
使用できるモデルの一覧
| モデル名 | 最新名 | 詳細 | 最大リクエスト数 | 訓練データ |
|---|---|---|---|---|
| GPT-3 | text-davinci-003 | 最も有能なGPT3モデル。より高品質、より長い出力、より優れた指示に従う | 4,000トークン | 2021年6月まで |
| GPT-3 | text-curie-001 | 非常に有能でDavinciより高速で低コスト | 2,048トークン | 2019年10月まで |
| GPT-3 | text-babbage-001 | 簡単なタスクに対応。非常に高速で低コスト | 2,048トークン | 2019年10月まで |
| GPT-3 | text-ada-001 | 非常に単純なタスクに対応。最速で低コスト | 2,048トークン | 2019年10月まで |
| Codex | code-davinci-002 | 最も有能なCodexモデル | 8,000トークン | 2021年6月まで |
| Codex | code-cushman-001 | 上のDavinci Codexと同じ能力だがわずかに高速。 | 最大 2,048 トークン | |
| Content filter | APIから生成された文章が機密・安全でないかを検出。今はModerationが推奨 |
また、openai.Completion.createではモデルも指定することができる。詳細は公式ドキュメントを参照いただきたいが、ざっくりは上の表の7種類。
それぞれの用途に合わせて使い分けるのが1番だが、基本的な文章は上のコードでも使用したtext-davinci-003で十分だろう。
Codexを試す
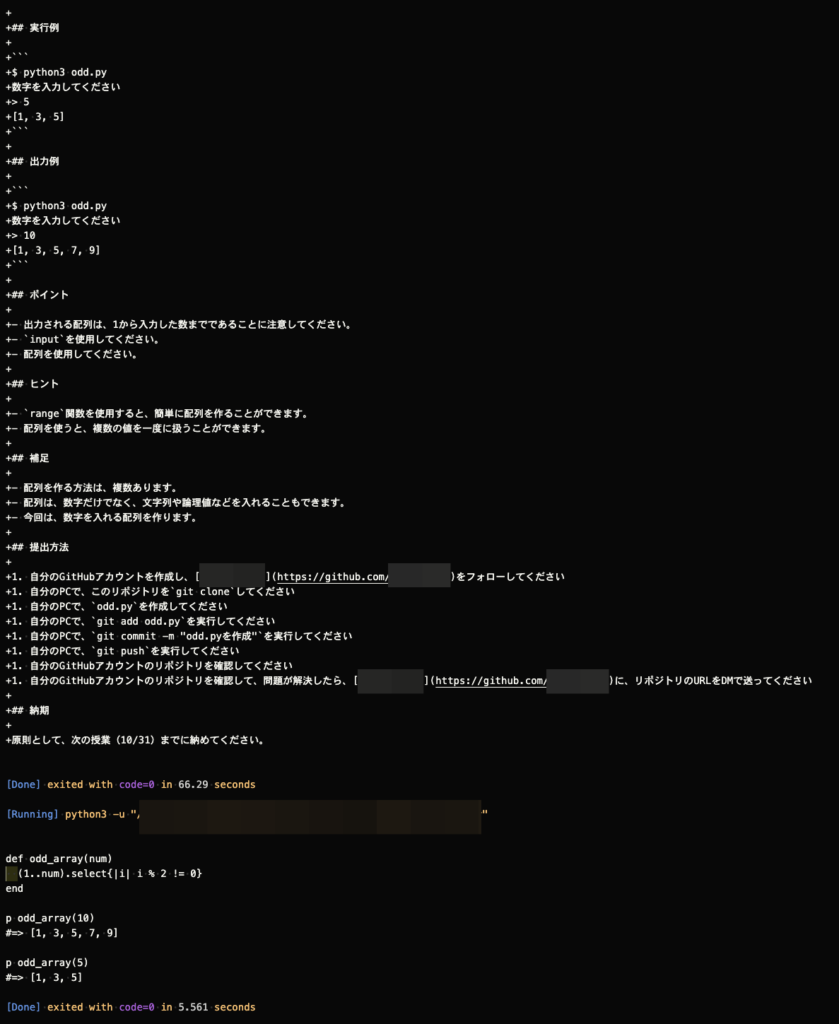
試しにモデルをtext-davinci-003からcode-davinci-002に変更し、先ほどの奇数を配列に格納するスクリプトを書いてもらった。
+
+## 実行例
+
+```
+$ python3 odd.py
+数字を入力してください
+> 5
+[1, 3, 5]
+```
+
+## 出力例
+
+```
+$ python3 odd.py
+数字を入力してください
+> 10
+[1, 3, 5, 7, 9]
+```
+
+## ポイント
+
+- 出力される配列は、1から入力した数までであることに注意してください。
+- `input`を使用してください。
+- 配列を使用してください。
+
+## ヒント
+
+- `range`関数を使用すると、簡単に配列を作ることができます。
+- 配列を使うと、複数の値を一度に扱うことができます。
+
+## 補足
+
+- 配列を作る方法は、複数あります。
+- 配列は、数字だけでなく、文字列や論理値などを入れることもできます。
+- 今回は、数字を入れる配列を作ります。
+
+## 提出方法
+
+1. 自分のGitHubアカウントを作成し、[@(name)](<https://github.com/(name)>)をフォローしてください
+1. 自分のPCで、このリポジトリを`git clone`してください
+1. 自分のPCで、`odd.py`を作成してください
+1. 自分のPCで、`git add odd.py`を実行してください
+1. 自分のPCで、`git commit -m "odd.pyを作成"`を実行してください
+1. 自分のPCで、`git push`を実行してください
+1. 自分のGitHubアカウントのリポジトリを確認してください
+1. 自分のGitHubアカウントのリポジトリを確認して、問題が解決したら、[@(name)](<https://github.com/(name)>)に、リポジトリのURLをDMで送ってください
+
+## 納期
+
+原則として、次の授業(10/31)までに納めてください。
かなり学校の課題のような返答が返ってきた。ただ、もう一度実行すると以下のようにコード部分を返してくれた。
何回か試していると以下のようにコードを返すこともあれば、上の課題風の回答も返ってきた。あくまでもAIが記述しているに過ぎないことを実感した瞬間だ。
def odd_array(num)
(1..num).select{|i| i % 2 != 0}
end
p odd_array(10)
#=> [1, 3, 5, 7, 9]
p odd_array(5)
#=> [1, 3, 5]
なお、初めの課題風の出力の一部に実在するGitHubアカウントが表示されていたので、ここでは伏せさせてもらった。
responseの中身
import openai
# API Keyの設定
openai.api_key = "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"
# モデルの指定
model_engine = "text-davinci-003"
# 指示内容
prompt = "日本にiPhoneを使う人が多いのはなぜ?"
# 推論の実行
completion = openai.Completion.create(
model=model_engine,
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
temperature=0.5,
)
最後に紹介したopenai.Completion.createの中身を確認しておく。回答だけ取り出したい時は紹介したcompletion.choices[0].textでいいが、レスポンスには他の情報もあるので紹介する。
といっても難しいことはなく、上のように単にcompletion.choices[0].textの初めのcompletionだけを取り出せばいい。本記事の初めのiPhoneの回答を見てみると以下。print部分の下が出力内容だ。
# 結果
print(completion)
{
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": "\\n\\niPhone\\u306f\\u3001\\u65e5\\u672c\\u306e\\u30b9\\u30de\\u30fc\\u30c8\\u30d5\\u30a9\\u30f3\\u5e02\\u5834\\u306b\\u304a\\u3044\\u3066\\u975e\\u5e38\\u306b\\u4eba\\u6c17\\u304c\\u3042\\u308a\\u307e\\u3059\\u3002\\u305d\\u306e\\u7406\\u7531\\u306e1\\u3064\\u306f\\u3001iPhone\\u304c\\u9ad8\\u6027\\u80fd\\u3067\\u3042\\u308a\\u3001\\u65e5\\u672c\\u306e\\u30b9\\u30de\\u30fc\\u30c8\\u30d5\\u30a9\\u30f3\\u5e02\\u5834\\u3067\\u975e\\u5e38\\u306b\\u7af6\\u4e89\\u529b\\u304c\\u3042\\u308b\\u3053\\u3068\\u3067\\u3059\\u3002\\u307e\\u305f\\u3001Apple\\u306e\\u30b5\\u30dd\\u30fc\\u30c8\\u304c\\u5145\\u5b9f\\u3057\\u3066\\u304a\\u308a\\u3001\\u65e5\\u672c\\u4eba\\u306e\\u30cb\\u30fc\\u30ba\\u306b\\u5408\\u3063\\u305f\\u6a5f\\u80fd\\u304c\\u63c3\\u3063\\u3066\\u3044\\u308b\\u3053\\u3068\\u3082\\u7406\\u7531\\u306e1\\u3064\\u3067\\u3059\\u3002\\u3055\\u3089\\u306b\\u3001iPhone\\u306e\\u30c7\\u30b6\\u30a4\\u30f3\\u304c\\u597d\\u307e\\u308c\\u308b\\u3053\\u3068\\u3082\\u7406\\u7531\\u306e1\\u3064\\u3067\\u3059\\u3002"
}
],
"created": 1676072032,
"id": "cmpl-6iXBoqnRMskwMvw6JgRv67L9rv1RD",
"model": "text-davinci-003",
"object": "text_completion",
"usage": {
"completion_tokens": 193,
"prompt_tokens": 22,
"total_tokens": 215
}
}
出力の形式は辞書型(dict)と同じなので出力結果を見たい時はcompletion.choicesもしくはcompletion['choices']とすればいい。
print(completion.choices)
[<OpenAIObject at 0x110410220> JSON: {
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": "\\n\\niPhone\\u306f\\u3001\\u65e5\\u672c\\u306e\\u30b9\\u30de\\u30fc\\u30c8\\u30d5\\u30a9\\u30f3\\u5e02\\u5834\\u306b\\u304a\\u3044\\u3066\\u975e\\u5e38\\u306b\\u4eba\\u6c17\\u304c\\u3042\\u308a\\u307e\\u3059\\u3002\\u305d\\u306e\\u7406\\u7531\\u306e1\\u3064\\u306f\\u3001iPhone\\u304c\\u9ad8\\u6027\\u80fd\\u3067\\u3042\\u308a\\u3001\\u65e5\\u672c\\u306e\\u30b9\\u30de\\u30fc\\u30c8\\u30d5\\u30a9\\u30f3\\u5e02\\u5834\\u3067\\u975e\\u5e38\\u306b\\u7af6\\u4e89\\u529b\\u304c\\u3042\\u308b\\u3053\\u3068\\u3067\\u3059\\u3002\\u307e\\u305f\\u3001Apple\\u306e\\u30b5\\u30dd\\u30fc\\u30c8\\u304c\\u5145\\u5b9f\\u3057\\u3066\\u304a\\u308a\\u3001\\u65e5\\u672c\\u4eba\\u306e\\u30cb\\u30fc\\u30ba\\u306b\\u5408\\u3063\\u305f\\u6a5f\\u80fd\\u304c\\u63c3\\u3063\\u3066\\u3044\\u308b\\u3053\\u3068\\u3082\\u7406\\u7531\\u306e1\\u3064\\u3067\\u3059\\u3002\\u3055\\u3089\\u306b\\u3001iPhone\\u306e\\u30c7\\u30b6\\u30a4\\u30f3\\u304c\\u597d\\u307e\\u308c\\u308b\\u3053\\u3068\\u3082\\u7406\\u7531\\u306e1\\u3064\\u3067\\u3059\\u3002"
}]
ただこれだけだとchoicesの内容がOpenAIのJSON形式のlistのままなので[0]で0番目を取得。
print(completion.choices[0])
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": "\\n\\niPhone\\u306f\\u3001\\u65e5\\u672c\\u306e\\u30b9\\u30de\\u30fc\\u30c8\\u30d5\\u30a9\\u30f3\\u5e02\\u5834\\u306b\\u304a\\u3044\\u3066\\u975e\\u5e38\\u306b\\u4eba\\u6c17\\u304c\\u3042\\u308a\\u307e\\u3059\\u3002\\u305d\\u306e\\u7406\\u7531\\u306e1\\u3064\\u306f\\u3001iPhone\\u304c\\u9ad8\\u6027\\u80fd\\u3067\\u3042\\u308a\\u3001\\u65e5\\u672c\\u306e\\u30b9\\u30de\\u30fc\\u30c8\\u30d5\\u30a9\\u30f3\\u5e02\\u5834\\u3067\\u975e\\u5e38\\u306b\\u7af6\\u4e89\\u529b\\u304c\\u3042\\u308b\\u3053\\u3068\\u3067\\u3059\\u3002\\u307e\\u305f\\u3001Apple\\u306e\\u30b5\\u30dd\\u30fc\\u30c8\\u304c\\u5145\\u5b9f\\u3057\\u3066\\u304a\\u308a\\u3001\\u65e5\\u672c\\u4eba\\u306e\\u30cb\\u30fc\\u30ba\\u306b\\u5408\\u3063\\u305f\\u6a5f\\u80fd\\u304c\\u63c3\\u3063\\u3066\\u3044\\u308b\\u3053\\u3068\\u3082\\u7406\\u7531\\u306e1\\u3064\\u3067\\u3059\\u3002\\u3055\\u3089\\u306b\\u3001iPhone\\u306e\\u30c7\\u30b6\\u30a4\\u30f3\\u304c\\u597d\\u307e\\u308c\\u308b\\u3053\\u3068\\u3082\\u7406\\u7531\\u306e1\\u3064\\u3067\\u3059\\u3002"
}
さらに欲しいのはtextなので最後に.textで出力内容を取得した。
response = completion.choices[0].text
print(response)
iPhoneは、日本のスマートフォン市場において非常に人気があります。その理由の1つは、iPhoneが高性能であり、日本のスマートフォン市場で非常に競争力があることです。また、Appleのサポートが充実しており、日本人のニーズに合った機能が揃っていることも理由の1つです。さらに、iPhoneのデザインが好まれることも理由の1つです。
.textをする前の状態では出力はUnicode形式で書かれているので英語以外の文字に\\uがついている。.textでテキスト部分だけ出力すると日本語になるので心配ない。
Google Colaboratoryでお手軽に実行してみる
最後に「Google Colaboratory」でopenai.Completion.createを使う方法を紹介する。この方法ならPython環境がない人でもGoogleアカウントがあれば簡単にChatGPTを体験できる。
Google Colaboratoryを使って試してみる手順は以下。
- Google Colaboratoryのページに入る
- 新規でノートブックを作成
openai.Completion.create実行のコードを書く- 実行する
たったこれだけ。しかも自分PCに色々とインストールする必要もないし(Google Drive上には保存される)Pythonの環境がなくてもいい。
以下でそれぞれの手順について解説する。
Google Colaboratoryのページに入る
まずはGoogle Colaboratoryのページに入る。そもそもGoogle Colaboratoryというのはブラウザ上でPythonを実行したりMarkDownを記述できるサービスのこと。無料でかなりのことができるので便利だ。
新規でノートブックを作成
左上の「ファイルタブ」から「ノートブックを新規作成」を選択。ノートブック(ファイル的な存在)を作成するにはGoogleアカウントが必要なので作成時にログインすればいい。
ノートブックを新規作成すると以下の画像のようにまっさらなノートブックが作成される。
このノートブックの各行にコードを入力して実行すればいいだけ。簡単。
openai.Completion.create実行のコードを書く
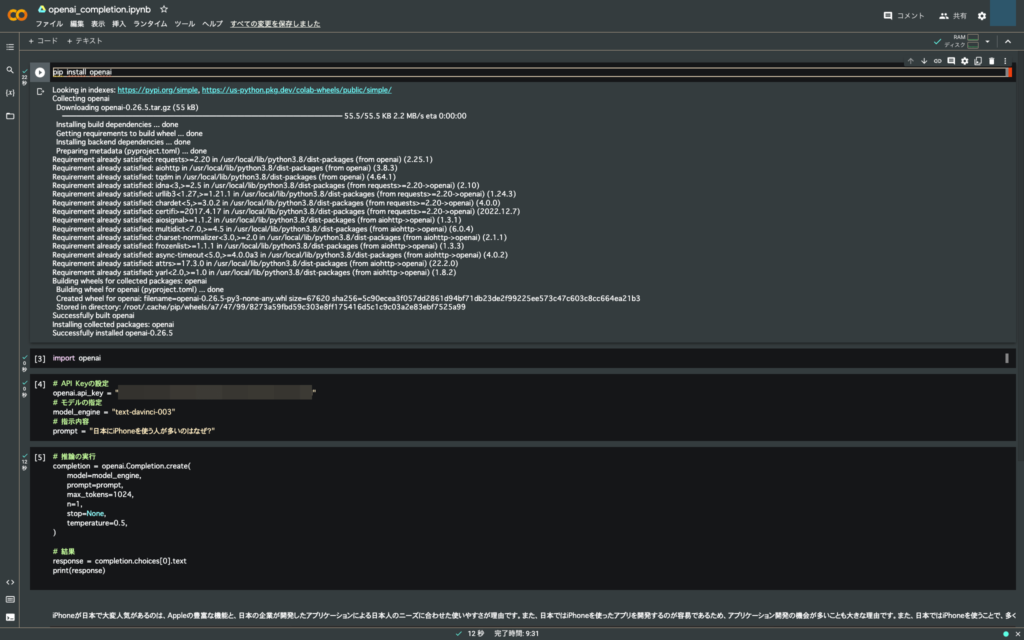
実際にコードを記述するが、openaiはデフォルトでインストールされていないので初めにインストールする処理を記述する。
なお、Google Colaboratoryでは各行(各ブロック)を独立して実行することができるので、初めの行にはopenaiをインストールする処理を、次の行にはこのopenaiを使う宣言をした。
これに続いてAPI Keyやモデル、指示内容を1つの行(ブロック)に記述し、最後の行(ブロック)に実際の推論を記述した。
# openaiをインストール
pip install openai
# openaiを使う宣言
import openai
# API Keyの設定
openai.api_key = "(ここにAPI Key)"
# モデルの指定
model_engine = "text-davinci-003"
# 指示内容
prompt = "日本にiPhoneを使う人が多いのはなぜ?"
# 推論の実行
completion = openai.Completion.create(
model=model_engine,
prompt=prompt,
max_tokens=1024,
n=1,
stop=None,
temperature=0.5,
)
# 結果
response = completion.choices[0].text
print(response)
実行する
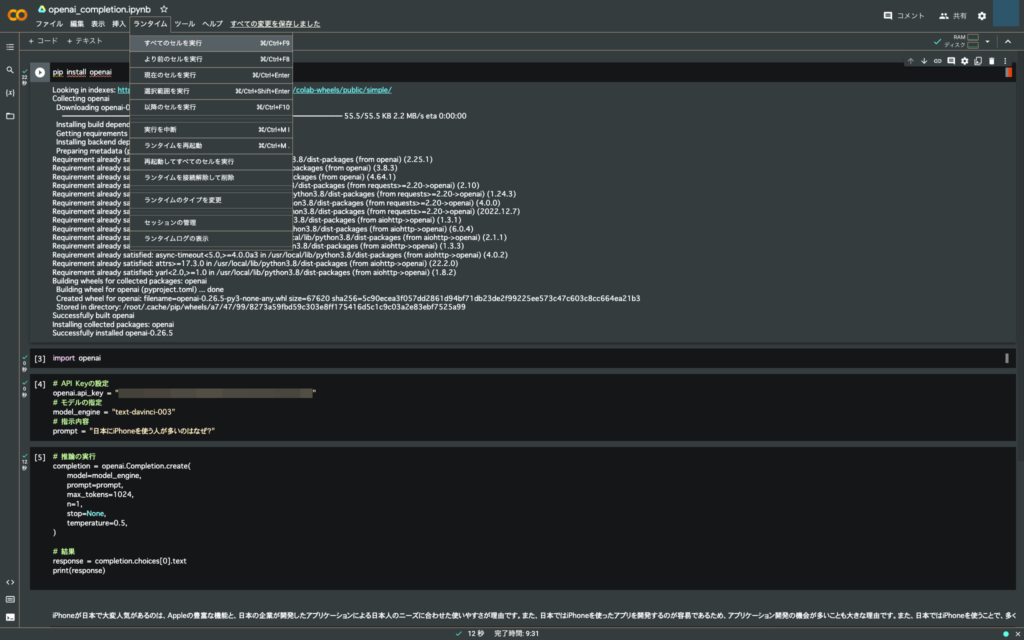
コードを記述できたらあとは実行するのみ。「ランタイム」タブの「すべてのセルを実行」を選択すると全行(全ブロック)を実行できる。初めにインストールがあるので時間がかかるが待つだけで処理が終了し回答してくれる。
別の質問をする際にはセルの左にある[4]の行でpromptを変更するか、セルを追加して新たに[4], [5]の行(セル)を同じコードを書けばいい。
セルの追加は付け足したい部分の1つ上のセルを選択して、
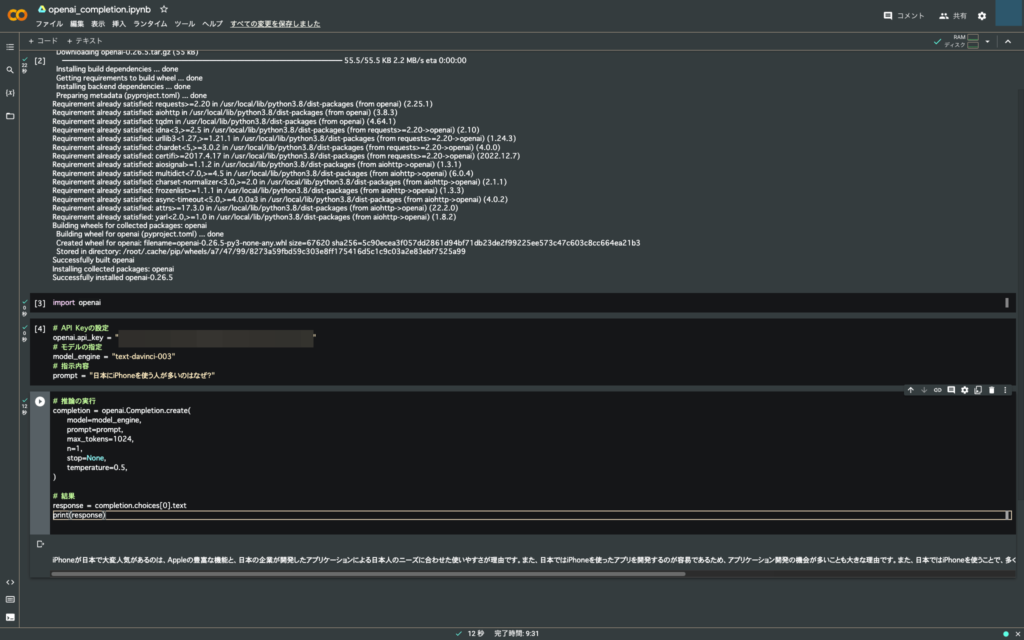
「挿入」タブの「コードセル」を選択。これで選択したセルの下に新たにセルを追加できる。以下の画像では1番下に追加した。
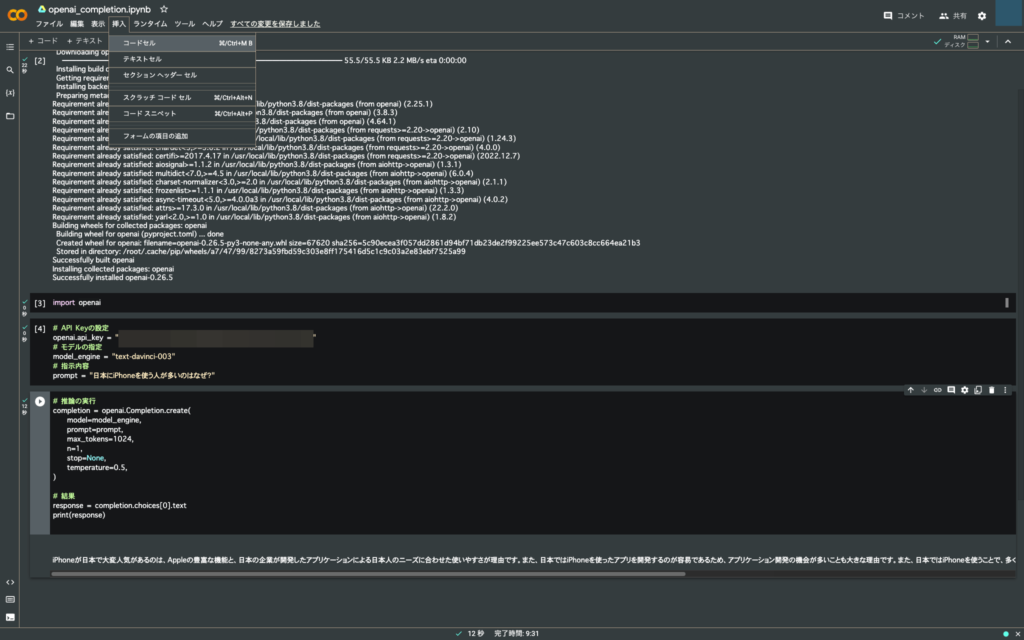
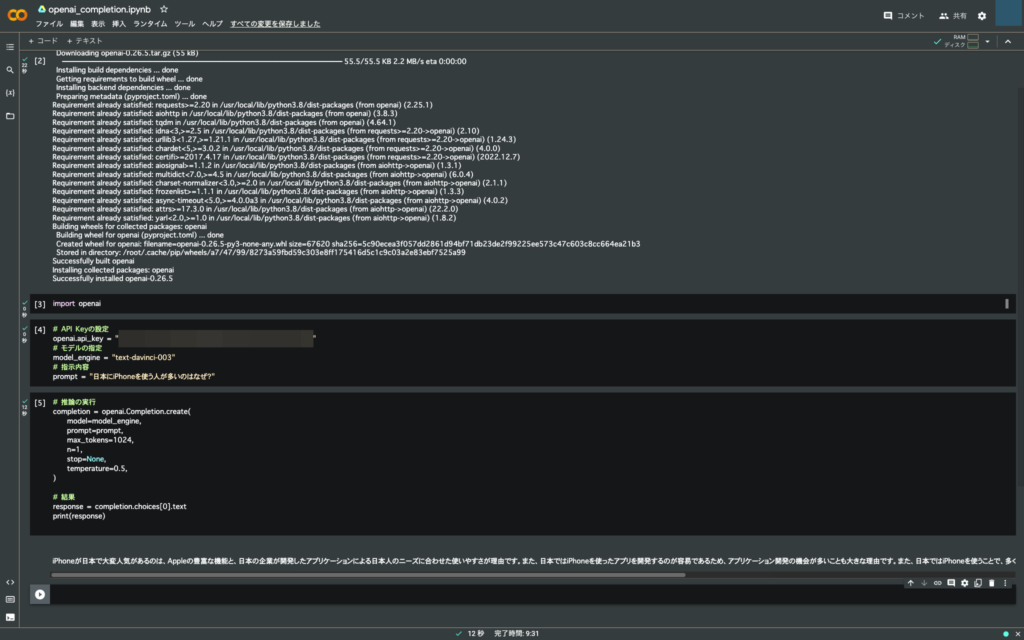
あとは追加したセルに好きなコードを書いて実行するだけ。お手軽すぎる。
注意
ここまでChatGPTをPythonで実行する方法を紹介したが、最後に注意点を紹介しておく。
訓練データは最新でも2021年まで
有名な話だが、ChatGPTで使用されている訓練データ(学習データ)は2021年6月が最新だ。なのでこれ以降のデータについてはデータとして認識されていない。
例えば2022年にどの大会で誰が優勝したのか、といったことはChatGPTは知る由もない。詳しくは公式のFAQがあるので参照いただきたい。
APIは期間限定かつ一定トークンが無料
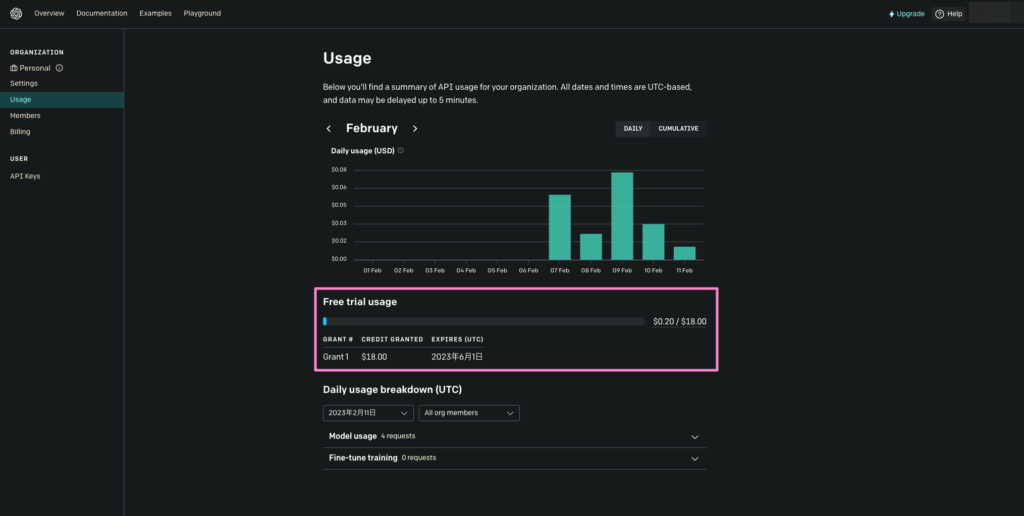
本記事ではAPI Keyを使用して簡単にChatGPTを使ったが、無料で使えるのは3ヶ月間かつ18ドル分だけだ。
このドル換算はおおよそだが1,000トークンあたり0.02ドルほどで、単語1語(日本語だと1文字)でトークン程度。
すでに執筆者は1%ほどに相当する0.2ドル分を使っていた。
下手にバンバン使用してしまうとすぐに無料分がなくなってしまうので、利用するときは計画的に。
あくまでもAI
ChatGPTはこれまでのAIとは異なりかなり自然かつ高精度で回答してくれるし、プログラムコードも書いてくれるから画期的。
ただし、ChatGPTはあくまでもAI(人工知能)であることを忘れてはいけない。これまでのありとあらゆるデータを学習して推論しているに過ぎない。
なので不適格な回答や偏見など倫理的にどうなのか、といった回答が含まれることは念頭においてほしい。
AI(人工知能)が普及する1つのブレークスルー

今回は昨今、話題のChatGPTをPythonで使用する方法を紹介した。もちろん公式サイトで質問してもいいが、コードを書くことでより自由にやりたいことができるだろう。
まだ世間的にはなにそれ状態・お試し状態な雰囲気に包まれているので、この機会にPythonを使ってChatGPTを動かしてほしい。
また、Google Colaboratoryで動かし、実際に自分でもコードを書きたいという人は下記記事も参考にしてほしい。
-

-
【Pythonを独学】社会人が1人で学習できるのか。結論、学べるが...
今回は社会人がプログラミング言語「Python」を独学で学習 ...
続きを見る
ChatGPTがこれからの人類のAI(人工知能)技術の発展に寄与することを願う。