これからPloltyで動くグラフを作りたい、もっとグラフをキレイに見せたい、後から簡単に見返せるグラフを作りたい。
そんな人はまずはPlotlyの基礎、pxの散布図グラフpx.scatterから始めてみよう。本記事ではpx.scatterの使い方をざっくりと解説する。
本記事の内容は以下。
- 1種類のデータのグラフを作成
- 複数種類のデータのグラフを作成
- 既存のプロットにプロットを追加
- プロット名や凡例タイトルを変更
- プロットの色やシンボルのサイズなどを変更
- カラーバーとシンボルの設定を両立
- エラーバーの追加
px.scatterの基礎的な使い方が凝縮されているし、それぞれの変数の中身や仕組みが分かれば他のPlotlyのグラフ化にも応用できる。
是非とも頑張って読み進めてほしい。本記事のPython環境は以下。
- Python 3.10.8
- numpy 1.24.0
- plotly 5.11.0
- plotly-orca 3.4.2
参考になるサイト
Plotly公式
本記事のコード全文
下準備のimport
import numpy as np
import pandas as pd
import plotly.express as px
import plotly.io as pio
import plotly.graph_objects as go
まずは下準備としてのimport関連。今回は基本pxを使用するが、一部データを作成・読み込みするためにnumpyとpandasを使用するのでimport。
また、pxだけでは賄いきれない処理についてはgoを使って実現するのでgoもimport。pioはplotlyでのグラフ保存用のライブラリ。保存の仕方は色々あるがpioその1つだ。
goを使った散布図(go.Scatter)の書き方については以下の記事で詳しく解説している。
-
-
【Plotlyで散布図】go.Scatterのグラフの描き方まとめ
これからPloltyで動くグラフを作りたい、もっとグラフをキ ...
続きを見る
1種類のデータをプロット
まずは簡単な1種類のデータをプロットする方法から解説する。プロットの方法は下記の2種類で、前者の方法がgo.Scatterでも使用した方法だ。
一方で後者の方法はpx特有のプロットの方法で、pandasのデータフレームがあるとすぐにグラフを作成することが可能だ。
x,yの配列から作成x,yの列のあるpandasのデータフレームから作成
この章ではこれら2種類のプロット方法を実際にグラフを用いながら解説する。
なお、go.ScatterではSが大文字である一方でpx.scatterのSは小文字だ。px.Scatterとしてしまうと以下のようなエラーとなる。
Traceback (most recent call last):
File "/(ファイルのあるディレクトリ)/(ファイル名).py", line 44, in <module>
fig = px.Scatter(
AttributeError: module 'plotly.express' has no attribute 'Scatter'. Did you mean: 'scatter'?
x, yの値を指定してプロット
まずはシンプルに、値を指定してプロットする方法から。この方法は単にx, yの値を配列で渡してあげるだけでいい。
pxではfigに直接px.scatterとするだけで自動でfigureが作成される。なのであとはfig.show()をするだけでグラフを作成することが可能だ。
あの、上のグラフでは本記事に掲載するに際してフォントサイズを変更している。
import plotly.express as px
import plotly.io as pio
# シンプルにデータをプロット
# x, yを指定してプロット
fig = px.scatter(
x=[0, 1, 2, 3, 4], # 横軸の値
y=[0, 1, 4, 9, 16], # 縦軸の値
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
# グラフの表示
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_xy"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
pandasデータフレームからプロット
続いてはpxの特徴とも言えるpandasのデータフレームを使ったグラフ作成方法だ。データの個数が増えてくるとpandasを使用する方がデータを扱いやすい。
上のグラフはシンプルにxとyというカラム名のデータフレームを使ってグラフ化した。px.scatterでの引数はdata_frameでデータフレームを、xとyで横軸・縦軸にしたいカラム名を指定する。
データフレームを使用することでプロットする対象をカラム名で指定することができる。
import pandas as pd
import plotly.express as px
import plotly.io as pio
# データフレームからプロット
df = pd.DataFrame({'x': [0, 1, 2, 3, 4], 'y': [0, 1, 4, 9, 16]})
print(df)
# x y
# 0 0 0
# 1 1 1
# 2 2 4
# 3 3 9
# 4 4 16
# データフレームのヘッダ名からx, yを指定してプロット
fig = px.scatter(
data_frame=df, # 使用するデータフレーム
x='x', # 横軸の値に設定するデータフレームの列名
y='y', # 縦軸に設定するデータフレームの列名
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
# グラフの表示
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
複数種のデータをプロット
続いては2種類以上のデータをプロットする場合だ。y1, y2, y3, …というデータをプロットするイメージだ。
シンプルに考えるとpx.scatterのx, yにそれぞれ2次元配列を渡してあげればいけそうだが、それではエラーになる。
# 複数プロットを2次元配列で指定するのはエラー
fig = px.scatter(
x=[[0, 1, 2, 3, 4], [0, 1, 2, 3, 4]],
y=[[0, 1, 4, 9, 16], [10, 12, 14, 19, 16]],
)
# ValueError: Cannot accept list of column references or list of columns for both `x` and `y`.
以下より複数種のデータをプロットする方法を解説する。
xを共通にすると複数プロットが可能
先ほどは2種類のxとyでグラフを作成しようとしてエラーとなったが、2種類のグラフは同じ横軸(x)の値を持つのが一般的。
なので、xは1次元配列にしてyは先ほどと同様2次元配列でグラフを作成するとうまくいく。
なお、この方法では凡例タイトルがvariableで各プロットの凡例がwide_variable_0, wide_variable_1になる。
import plotly.express as px
import plotly.io as pio
# xは共通とする必要がある
fig = px.scatter(
x=[0, 1, 2, 3, 4],
y=[[0, 1, 4, 9, 16], [10, 12, 14, 19, 16]],
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_1xy2_scatter"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
1カラムしかないpandasのデータフレームで複数プロット
続いてはpxの特徴であるpandasのデータフレームを使ってのプロット方法。ただし、この場合も先ほどと同様、複数のデータに対して共通の横軸の値が必要になる。
1カラムしか持たないpandasのデータプロットの場合、データフレームの初めに1プロット目のx, yの値、その下に2プロット目のx, yの値、というように縦に並べないといけない。
配列からデータフレームを作成する場合、例えば以下のように作成することが可能だ。
import pandas as pd
import plotly.express as px
import plotly.io as pio
df = pd.DataFrame(
{
'x': [0, 1, 2, 3, 4] + [0, 1, 2, 3, 4],
'y': [0, 1, 4, 9, 16] + [10, 12, 14, 19, 16],
'name': ['data0'] * 5 + ['data1'] * 5,
}
)
print(df)
# x y name
# 0 0 0 data0
# 1 1 1 data0
# 2 2 4 data0
# 3 3 9 data0
# 4 4 16 data0
# 5 0 10 data1
# 6 1 12 data1
# 7 2 14 data1
# 8 3 19 data1
# 9 4 16 data1
x列とname列を見るとわかるように、data0でxを0~4まで作成、その下にdata1のデータを並べている。
このデータフレームを作成することができたら、あとは1データのプロットと同じようにpx.scatterの引数にdfとx, y列を指定するだけだ。
import pandas as pd
import plotly.express as px
import plotly.io as pio
# データフレームがあれば列名を指定するだけ
df = pd.DataFrame(
{
'x': [0, 1, 2, 3, 4] + [0, 1, 2, 3, 4],
'y': [0, 1, 4, 9, 16] + [10, 12, 14, 19, 16],
'name': ['data0'] * 5 + ['data1'] * 5,
}
)
print(df)
# x y name
# 0 0 0 data0
# 1 1 1 data0
# 2 2 4 data0
# 3 3 9 data0
# 4 4 16 data0
# 5 0 10 data1
# 6 1 12 data1
# 7 2 14 data1
# 8 3 19 data1
# 9 4 16 data1
fig = px.scatter(
df, x='x', y='y',
color='name' # 色を区別する列名
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# # グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_df_2plots"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
既存のプロットにプロットを追加
複数種のプロットをデータフレームを使用して実現したが、ここではすでにグラフ化したプロットに追加でデータを追加する方法を解説する。
pxに限った話ではないのでPlotly内で応用が効くが、この機会に解説しておく。
fig.add_traces, fig.add_scatterでプロットを追加
複数カラムあるデータを追加する場合だが、px.scatter単体では上記の1カラムに全データの入ったデータフレームを使用するのが基本。
なのでpx.scatterだけで複数カラムのプロットを実現するのは無理。fig.add_trace(s)もしくは散布図に限るならfig.add_scatterを使用することで散布図を追加することが可能だ。
2プロット以上を一括で追加したい場合はfig.add_tracesを使うと楽に記述することが可能だ。
# 2プロット目(追加分)
fig.add_scatter(x=[0, 1, 2, 3, 4], y=[10, 12, 14, 19, 16])
fig.add_traces(go.Scatter(x=[0, 1, 2, 3, 4], y=[10, 12, 14, 19, 16]))
# 3プロット目以降を追加するならadd_tracesの方が楽
fig.add_traces(
(
go.Scatter(x=[0, 1, 2, 3, 4], y=[10, 12, 14, 19, 16]),
go.Scatter(x=[0, 1, 2, 3, 4], y=[11, 15, 11, 17, 11])
)
)
ただ、このままではaddしたプロットの凡例が表示され、px.scatterで作成したプロットの凡例が表示されないが、これについては後述。
import pandas as pd
import plotly.express as px
import plotly.io as pio
# 既存のfigにプロットを追加
# 1プロット目
fig = px.scatter(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16])
# 2プロット目(追加分)
fig.add_scatter(x=[0, 1, 2, 3, 4], y=[10, 12, 14, 19, 16])
# fig.add_traces(go.Scatter(x=[0, 1, 2, 3, 4], y=[10, 12, 14, 19, 16]))
# # 3プロット目以降を追加するならadd_tracesの方が楽
# fig.add_traces(
# (
# go.Scatter(x=[0, 1, 2, 3, 4], y=[10, 12, 14, 19, 16]),
# go.Scatter(x=[0, 1, 2, 3, 4], y=[11, 15, 11, 17, 11])
# )
# )
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_add_scatter"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
figのデータ部分だけ取り出して結合
addを使う方法でもプロットを追加することはできるが、この方法だと1プロット目はpxを使用し、それ以降のプロットはaddを使うことになるので統一感がない。
全プロットをpxを使ってfigとして作成し、これらのfigのdata部分だけを取り出して結合し、これを全体のグラフのデータ部分とすると統一感が出る。
ただし、この場合でもpxだけで完結することはできず、結局はgoを使用することになる。
また、fig0, fig1ともに別のfigを作成することになるので、両方のプロットカラーがデフォルトの#636efaだ。なので判別ができるようにfig作成後にわざわざ色指定する必要がある。
import pandas as pd
import plotly.express as px
import plotly.io as pio
import plotly.graph_objects as go
# fig.dataでデータ部分だけ結合してグラフ化
# fig作成後にプロットカラーを変更しないと同じ色(#636efa)になる
fig0 = px.scatter(x=[0, 1, 2, 3, 4], y=[0, 1, 4, 9, 16])
fig0['data'][0]['marker']['color'] = 'red'
fig1 = px.scatter(x=[0, 3, 4, 5, 6], y=[2, 6, 4, 12, 18])
fig1['data'][0]['marker']['color'] = 'blue'
#2種類のfigのdata部分だけを結合
fig = go.Figure(data=fig0.data+fig1.data)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_figdata_scatter"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
プロット名と凡例のタイトルを変更
ここまでで複数プロットを作成する方法を紹介したが、グラフによれば凡例がつかなかったり凡例タイトルを変更したい場合もあるだろう。
各プロットの凡例名(プロット名)fig['data'][0]['name']で変更可能だ。インデックスはプロットする順番。また、凡例タイトルはlayoutのlegend_title(legend=dict(title=))で変更可能だ。
上のグラフではpandasのデータフレームを例にしたが、もちろん配列でのグラフでも同様に変更可能だ。
import pandas as pd
import plotly.express as px
import plotly.io as pio
# プロット名と凡例タイトルを変更
df = pd.DataFrame(
{
'x': [0, 1, 2, 3, 4] + [0, 1, 2, 3, 4],
'y': [0, 1, 4, 9, 16] + [10, 12, 14, 19, 16],
'name': ['data0'] * 5 + ['data1'] * 5,
}
)
print(df)
# x y name
# 0 0 0 data0
# 1 1 1 data0
# 2 2 4 data0
# 3 3 9 data0
# 4 4 16 data0
# 5 0 10 data1
# 6 1 12 data1
# 7 2 14 data1
# 8 3 19 data1
# 9 4 16 data1
fig = px.scatter(
df, x='x', y='y',
color='name' # 色を区別する列名
)
# プロット名と凡例のタイトルを変更
print(fig['data'][0]) # wide_variable_0のプロット情報を取得
# Scatter({
# 'hovertemplate': 'name=data0<br>x=%{x}<br>y=%{y}<extra></extra>',
# 'legendgroup': 'data0',
# 'marker': {'color': '#636efa', 'symbol': 'circle'},
# 'mode': 'markers',
# 'name': 'data0',
# 'orientation': 'v',
# 'showlegend': True,
# 'x': array([0, 1, 2, 3, 4]),
# 'xaxis': 'x',
# 'y': array([ 0, 1, 4, 9, 16]),
# 'yaxis': 'y'
# })
fig['data'][0]['name'] = 'plot1' # プロット名の変更
fig.update_layout(legend_title='legend title') # 凡例タイトルの変更
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_1xy2_scatter_change_label"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
色やシンボルのサイズ・形状でデータを分ける
続いては複数データを、そのデータごとに色やシンボル(マーカー)のサイズ・形状で分ける方法を紹介する。
px.scatterでは引数にデータフレームのカラム名を指定することで、勝手に判別して分けてくれる。
使用するデータはPlotly公式でも使用されている、以下のあやめに関するpandasのデータフレームだ。ヘッダ名とあやめの種類のカラムの内容も併記しておく。
import pandas as pd
import plotly.express as px
import plotly.io as pio
# 使用するあやめに関するデータ
df = px.data.iris()
print(df)
# sepal_length sepal_width ... species species_id
# 0 5.1 3.5 ... setosa 1
# 1 4.9 3.0 ... setosa 1
# 2 4.7 3.2 ... setosa 1
# 3 4.6 3.1 ... setosa 1
# 4 5.0 3.6 ... setosa 1
# .. ... ... ... ... ...
# 145 6.7 3.0 ... virginica 3
# 146 6.3 2.5 ... virginica 3
# 147 6.5 3.0 ... virginica 3
# 148 6.2 3.4 ... virginica 3
# 149 5.9 3.0 ... virginica 3
# [150 rows x 6 columns]
# ヘッダ名の取得
print(df.columns.values)
# ['sepal_length' 'sepal_width' 'petal_length' 'petal_width' 'species'
# 'species_id']
# 種類のデータ
print(df['species'].unique())
# ['setosa' 'versicolor' 'virginica']
colorとsizeで色とシンボルのサイズを分ける
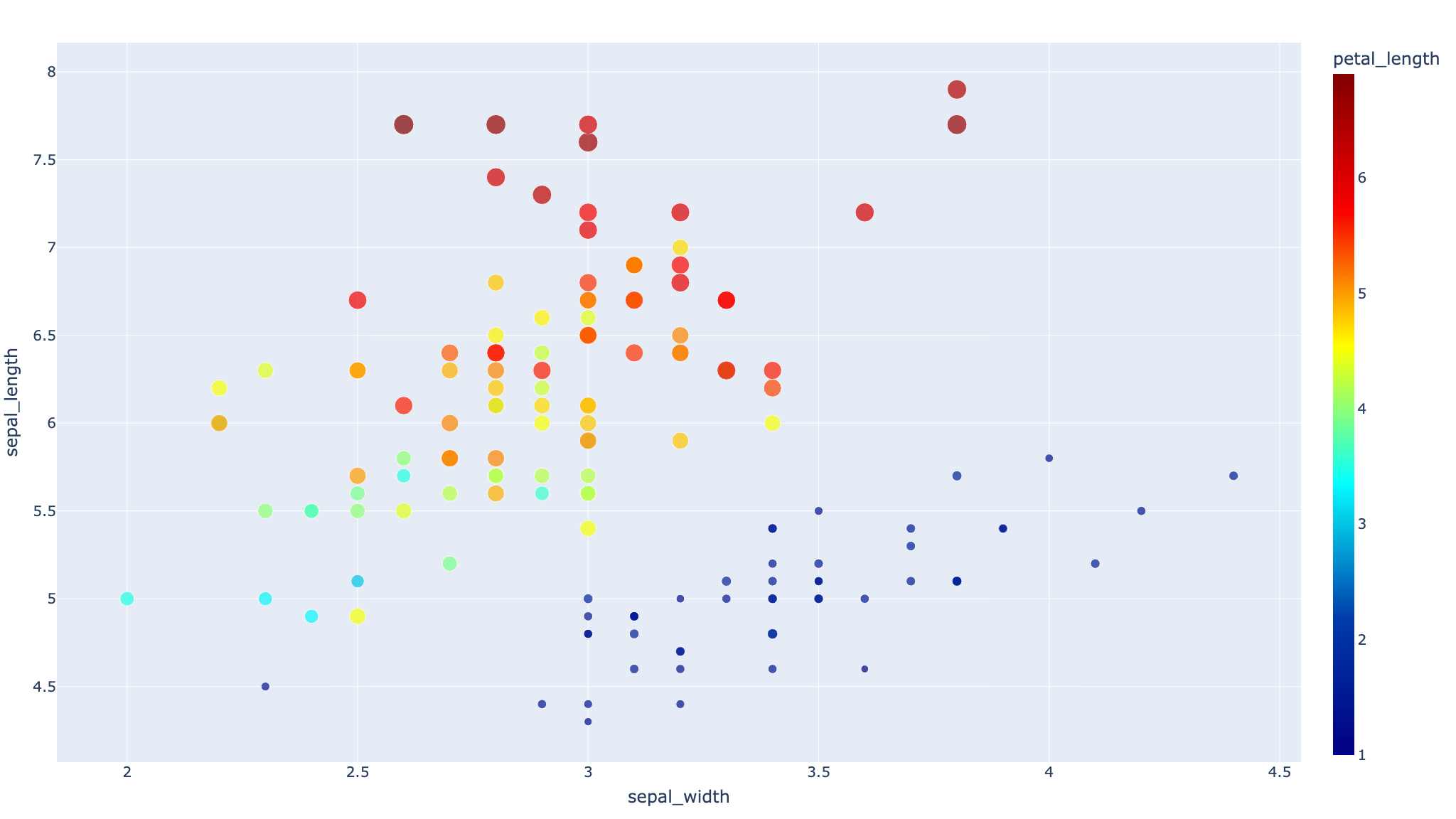
px.scatterの引数colorとsizeに分ける基準になるデータフレームのカラム名を指定することで、自動でシンボルの色とサイズを変更してくれる。
ここでは色をあやめの種類’species’、シンボルのサイズをそれぞれのあやめの花びら(花弁)の長さ’petal_length’に指定した。
また、colorで’species’を指定したので、自動で凡例も’species’に合わせて表示してくれている。ありがたい。
import pandas as pd
import plotly.express as px
import plotly.io as pio
# データによってプロットの色とマーカーのサイズを変更
# あやめに関するデータ
df = px.data.iris()
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
color='species', # species列の名称で色分け
size='petal_length', # マーカーのサイズをpetal_lengthで決める
hover_data=df, # データフレームを選択すると全ヘッダ情報が表示される
# hover_data=['petal_width'], # 列名指定するときはlistかtupleで指定
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_color_size_str"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
colorを数値データにするとカラーバーが自動で表示
先ほどのグラフではpx.scatterの引数colorを文字列であるあやめの種類’species’に指定したが、colorに数値データのカラムを指定すると自動でカラーバーが表示される。
上のグラフではcolorに’petal_length’を指定したが、この場合は全種類のあやめが1つのカラーバーに集約されるのでかなり見づらい。
一応、マーカーの形状をあやめの種類ごとに変えることで、カラーバーが同じでも種類を見分けることができる。この方法については後述。
import pandas as pd
import plotly.express as px
import plotly.io as pio
# 数値で色分けすると自動でカラーバーがつく
df = px.data.iris()
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
color='petal_length', # 数値で色分けすると自動でカラーバーで示してくれる
size='petal_length', # マーカーサイズも同じ列名で可能
hover_data=df, # データフレームを選択すると全ヘッダ情報が表示される
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_color_size_value"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
カラースケールの変更はcolor_continuous_scale
カラーバーの色(カラースケール)の変更は引数のcolor_continuous_scaleを使用すると可能だ。この引数にカラースケールの名称や色の配列を入れるだけ。
以下の3種類の方法から指定可能だ。
- 既存のカラースケールで指定
- ex:
'jet'
- ex:
- 色の配列の形式で指定
- ex:
['red', 'blue', 'yellow']
- ex:
- 色と位置の2次元配列の形式で指定
- ex:
[[0, 'green'], [0.1, 'red'], [1.0, 'rgb(0, 0, 255)']]
- ex:
import pandas as pd
import plotly.express as px
import plotly.io as pio
# カラースケールの変更はcolor_continuous_scale
df = px.data.iris()
color_continuous_scales = {
'colorscale': 'jet', # カラースケール名
'color_array': ['green', 'red', 'rgb(0, 0, 255)'], # 色
'color_position_array': [[0, 'green'], [0.1, 'red'], [1.0, 'rgb(0, 0, 255)']] # 位置と色
}
for name, color_continuous_scale in color_continuous_scales.items():
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
color='petal_length', # 数値で色分けすると自動でカラーバーで示してくれる
size='petal_length', # マーカーサイズも同じ列名で可能
hover_data=df, # データフレームを選択すると全ヘッダ情報が表示される
color_continuous_scale=color_continuous_scale
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_color_size_value_{name}"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
sizeに文字列があるとエラー
px.scatterの引数sizeにデータフレームのカラム名を指定することでシンボルのサイズを変えることができた。
しかし、この引数sizeに文字列を指定するとエラーになることに注意。sizeでデータの区別をする際には、そのデータごとに固有の数値を割り振る必要がある。
import plotly.express as px
import plotly.io as pio
df = px.data.iris()
print(df['species'])
# 0 setosa
# 1 setosa
# 2 setosa
# 3 setosa
# 4 setosa
# ...
# 145 virginica
# 146 virginica
# 147 virginica
# 148 virginica
# 149 virginica
# Name: species, Length: 150, dtype: object
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
size='species', # サイズに文字の列を指定
)
# TypeError: unsupported operand type(s) for /: 'str' and 'int'
今回使用しているあやめのデータは偶然にも'species_id'というカラムがあり、種類ごとに0から番号が振られているのでこれを使用することができる。
ただ、上のグラフを見るとわかるように、この'species_id'は値の差が小さいのでシンボルのサイズとして見分けるのが難しい。
import plotly.express as px
import plotly.io as pio
df = px.data.iris()
# species_idを使えばその種類ごとにシンボルのサイズを変更可能
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
size='species_id', # サイズに文字の列を指定
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_size_species_id"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
IDのカラムを追加してシンボルのサイズを設定
デフォルトの'species_id'だとサイズが小さかったので、ここでは新たに'unique_id'カラムを追加し、このカラムのを'species_id'の3乗になるようにした。
単に'species_id'を3乗するだけだと新規で作成するときに使えないので、ここでは新しく1からカラムを作成・計算した。手順は以下。
'species'カラムのユニークを取得- このユニークな値ごとにforループ
condlistに各行がユニークな値か判定choicelistにユニークIDを格納
np.selectで'unique_id'列を追加
3乗くらいにするとサイズの違いがわかりやすかった。ここは適宜変更してほしい。この方法でできたグラフが上のグラフで、種類ごとにサイズが変わっている。
import numpy as np
import pandas as pd
import plotly.express as px
import plotly.io as pio
df = px.data.iris()
# 以下のように別でIDを作成することも可能
condlist = []
choicelist = []
for num, species in enumerate(df['species'].unique(), 1):
condlist.append(df['species'] == species)
choicelist.append(num **3)
# dfに種類に応じたIDに対応した新しいカラムを追加
df['unique_id'] = np.select(condlist=condlist, choicelist=choicelist, default=0)
print(df)
# sepal_length sepal_width petal_length ... species species_id unique_id
# 0 5.1 3.5 1.4 ... setosa 1 1
# 1 4.9 3.0 1.4 ... setosa 1 1
# 2 4.7 3.2 1.3 ... setosa 1 1
# 3 4.6 3.1 1.5 ... setosa 1 1
# 4 5.0 3.6 1.4 ... setosa 1 1
# .. ... ... ... ... ... ... ...
# 145 6.7 3.0 5.2 ... virginica 3 27
# 146 6.3 2.5 5.0 ... virginica 3 27
# 147 6.5 3.0 5.2 ... virginica 3 27
# 148 6.2 3.4 5.4 ... virginica 3 27
# 149 5.9 3.0 5.1 ... virginica 3 27
# [150 rows x 7 columns]
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
size='unique_id', # サイズに文字の列を指定
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_unique_id"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
symbolでシンボルの形状を変更
px.scatterの引数symbolでシンボルの形状を変更することも可能だ。指定の方法はこれまでのcolorやsizeと同様、データフレームのカラム名を指定するだけだ。ここではあやめの種類'species'を指定した。
import plotly.express as px
import plotly.io as pio
# マーカーの形状を変更
df = px.data.iris()
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
size='petal_length',
symbol='species', # speciesでマーカーの形状を指定&凡例も自動作成
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_symbol"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
カラーバーとシンボルのサイズ・形状を同時に使う
ここまででpx.scatterを使ってカラーバーを表示し、シンボルのサイズや形状を変更する方法を紹介した。しかし、これらの解説はあくまでもうまくいく状況下だった。
上のグラフのようにcolorとsizeを同時に使用した場合、グラフの凡例とカラーバーが重なって表示されてしまう。
一応、カラーバーの隙間から凡例をクリックしてグラフの表示・非表示は可能だが、見た目も操作性も良くない。
ということで、ここではカラーバーとシンボルのサイズ・形状を同時にうまく使用する方法を解説する。
import plotly.express as px
import plotly.io as pio
# 凡例とカラーバーの両立だと位置がダブる
df = px.data.iris()
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
size='petal_length', # サイズ
color='petal_length', # 色
symbol='species', # 形状
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_color_symbol_size_bad"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
凡例をグラフ枠内の右上に移動
シンプルな方法として凡例の場所を移動させるというものがある。上のグラフでは凡例をグラフ枠内の右上に位置するように調節した。
px.scatterでfigを作成した後、fig.update_layoutでlegendのxの位置をx=1、xの位置基準xanchor=’right’とすることで枠内の右上に移動させることが可能。
これで凡例とカラーバーが独立するので見栄えも良く操作性も保たれる。
import plotly.express as px
import plotly.io as pio
# 凡例の位置と位置基準をグラフ枠内の右上に変更
df = px.data.iris()
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
size='petal_length', # サイズ
color='petal_length', # 色
symbol='species', # 形状
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
# 凡例の横位置を1にして位置基準を右に設定
fig.update_layout(legend=dict(x=1, xanchor='right'))
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_color_symbol_size_legend"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
カラーバーの位置を右に変更
逆にカラーバーの位置を変更することも可能だが、カラーバーは長くて目盛もあるのでかなりの領域をとってしまう。
なので凡例のちょうど右側にくっつける形に配置したいが、現状のPlotlyでは凡例の幅を取得することはできなさそう(凡例の初期位置は1.02で決まっている。リファレンス参照)。
なので、ちょうどいい感じの位置にカラーバーが来るように調節したが、グラフのサイズを変えるたびに調節しないといけないのがネック。なお、カラーバー関係はレイアウトのcoloraxis_colorbarで設定可能。
import plotly.express as px
import plotly.io as pio
# カラーバーを凡例の右側に移動
df = px.data.iris()
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
size='petal_length', # サイズ
color='petal_length', # 色
symbol='species', # 形状
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
# カラーバーの位置をいい感じの位置に変更
fig.update_layout(coloraxis_colorbar=dict(x=1.1, xanchor='left'))
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_color_symbol_size_legend_position"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
カラーバーの長さを短くする
凡例やカラーバーの位置を調節するだけでなく、カラーバーの長さを変更することも可能だ。変更はcoloraxis_colorbarのlenで可能。上のグラフでは0.5にした。
また、単に長さを変更するだけだとカラーバーが中央付近に位置するので、y=0とyanchor=’bottom’でグラフ枠の下を底辺とするように調節した。
import plotly.express as px
import plotly.io as pio
# カラーバーの長さを変更
df = px.data.iris()
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
size='petal_length', # サイズ
color='petal_length', # 色
symbol='species', # 形状
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
# カラーバーを短くする
fig.update_layout(coloraxis_colorbar=dict(len=0.5, y=0, yanchor='bottom'))
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_color_symbol_size_colorbar_barlen"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
カラーバーを横向き(水平)に配置
カラーバーの位置を変更したり長さを調節したりする方法は解説したが、どちらもグラフのサイズが変わるとバランスが悪くなる。
上のグラフではカラーバーの向きを縦向きから横向きにしたが、これだとグラフのサイズが変わってもちょうど良い位置にカラーバーを配置できる。
指定はcoloraxis_colorbarのorientation=’h’で可能。もちろんデフォルトはorientation='v'で垂直だ。
import plotly.express as px
import plotly.io as pio
# カラーバーを横向き(水平)に配置
df = px.data.iris()
fig = px.scatter(
df, x='sepal_width', y='sepal_length',
size='petal_length', # サイズ
color='petal_length', # 色
symbol='species', # 形状
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
# カラーバーを短くする
fig.update_layout(coloraxis_colorbar=dict(orientation='h'))
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_color_symbol_size_colorbar_horizon"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
error_x, error_yでエラーバーを追加する
データの種類によってはエラーバー(誤差棒)をつけたい時もあるだろう。その時はpx.scatterの引数error_xyでデータフレームのカラム名や配列を渡すことで追加可能だ。
ここでは簡単にsepal_length, sepal_width列を100で割った数値を新しいカラムとして作成、これらのカラムを使ってエラーバーを追加した。
なお、error_xではプラス方向とマイナス方向どちらも同じ値が適用されるが、引数error_x_minusを使用することでマイナス方向のエラーバーの数値を変更できる。
import plotly.express as px
import plotly.io as pio
df = px.data.iris()
# エラーの値を適当に作成
df['e_x'] = df['sepal_width'] / 100
df['e_y'] = df['sepal_length'] / 100
print(df)
# sepal_length sepal_width petal_length ... species_id e_x e_y
# 0 5.1 3.5 1.4 ... 1 0.035 0.051
# 1 4.9 3.0 1.4 ... 1 0.030 0.049
# 2 4.7 3.2 1.3 ... 1 0.032 0.047
# 3 4.6 3.1 1.5 ... 1 0.031 0.046
# 4 5.0 3.6 1.4 ... 1 0.036 0.050
# .. ... ... ... ... ... ... ...
# 145 6.7 3.0 5.2 ... 3 0.030 0.067
# 146 6.3 2.5 5.0 ... 3 0.025 0.063
# 147 6.5 3.0 5.2 ... 3 0.030 0.065
# 148 6.2 3.4 5.4 ... 3 0.034 0.062
# 149 5.9 3.0 5.1 ... 3 0.030 0.059
# [150 rows x 8 columns]
fig = px.scatter(
df, x='sepal_width', y='sepal_length', color='species',
error_x='e_x', error_y='e_y', # エラーバーの追加
)
# グラフ全体とホバーのフォントサイズ変更
fig.update_layout(font_size=20, hoverlabel_font_size=20)
fig.show()
# グラフ保存
prefix = 'px-scatter' # 保存ファイル名の接頭辞
save_name = f"{prefix}_error_xy"
pio.orca.config.executable = '/Applications/orca.app/Contents/MacOS/orca'
pio.write_html(fig, f"{save_name}.html")
pio.write_image(fig, f"{save_name}.png")
まずは基本から学ぶ
ということで、今回はplotlyのpxを使って散布図を作成する方法を解説した。散布図は基本的なグラフなので紹介した内容以外でもいろいろカスタムできるが、まずは基本から学んでほしい。
といったものの、本記事の内容を応用すれば他の種類のグラフも同じように作成することできる。なのでまずは本記事の内容やplotlyのグラフ作成の手順を知り、身につけてほしい。
以下の記事ではより細かくグラフを作成可能なgo(plotly.graph_objects)で散布図を描くことができるgo.Scatterを解説している。自由度高くグラフを作成したい人は必見だ。
-
-
【Plotlyで散布図】go.Scatterのグラフの描き方まとめ
これからPloltyで動くグラフを作りたい、もっとグラフをキ ...
続きを見る
関連記事
-
-
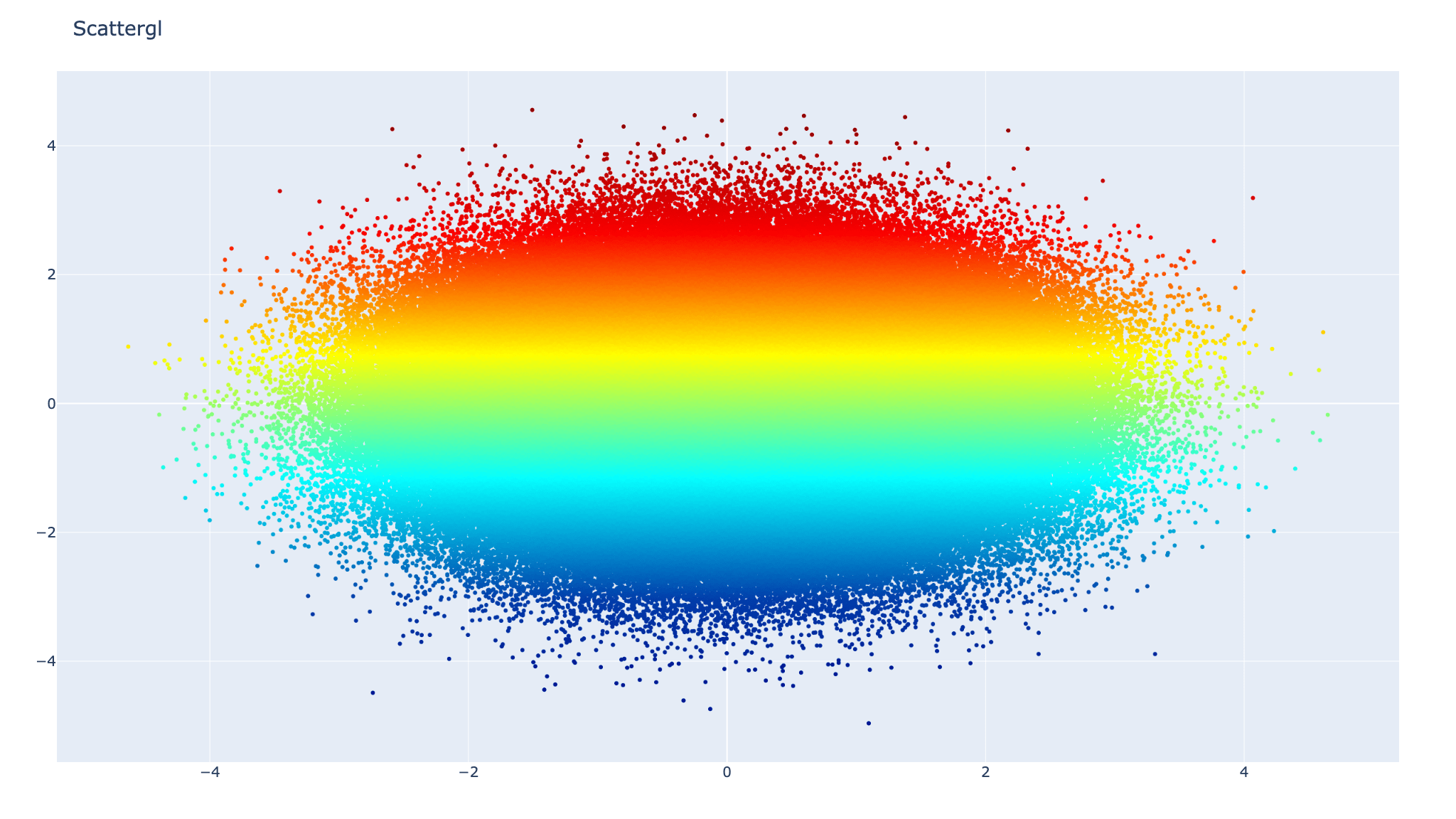
【Plotlyで散布図】go.Scatterglで大量のデータでグラフを作成する
今回はPythonのPlotlyで大量のデータを軽く扱うことができるgo.Scattergl ...
続きを見る
-
-
【Plotly&ボタン】updatemenusとbuttonsでボタン機能を追加
Plotlyはプロットしたデータを動かすことができるのが大き ...
続きを見る
-
-
【Plotly&ボタン】updatemenusのargs2で2回目のボタン押下機能を追加
今回はPlotlyのボタン機能に2回目のボタン押下の処理を追加& ...
続きを見る
-
-
【Plotly&sliders】スライダーを追加しデータを切り変える
本記事ではPlotlyでデータの流れを簡単に理解できる機能の ...
続きを見る
-

-
【Pythonを独学】社会人が1人で学習できるのか。結論、学べるが...
今回は社会人がプログラミング言語「Python」を独学で学習 ...
続きを見る